Einleitung: Das Speichern-Problem
Das WWW ist eine der relevantesten Informationsquellen für die eigene Wissensbasis. Daher sollte es einfach sein, schnell Links, Zitate oder ganze Artikel in Obsidian zu übernehmen und dort weiterzuverarbeiten. Wie dies mit dem Obsidian Web Clipper zu realisieren ist, soll dieser Artikel zeigen.
Zunächst möchte ich aber kurz auf die unterschiedlichen Arten des Speicherns von Web-Inhalten eingehen, denn nicht jede Methode eignet sich für jeden Zweck.
1. Lesezeichen oder Bookmarks
Alle Browser bieten zum Speichern und Verwalten von Lesezeichen eigene Funktionen. So ist ein interessanter Artikel oder ein ganzer Blog schnell als Lesezeichen abgelegt und jederzeit wieder aufrufbar.
Das klingt praktischer als es ist. Lesezeichenlisten wachsen schnell, veralten, und waren in frühen Browsern obendrein nur lokal gespeichert, also an einen einzigen Rechner gebunden. Wer von mehreren Geräten arbeiten wollte, hatte schlicht Pech. Mitte der 1990er Jahre entstanden deshalb die ersten Online-Dienste, die Lesezeichen in die Cloud verlagerten und von überall zugänglich machten.
Da nun die Bookmarks schon im Web erreichbar waren, war es naheliegend auch Funktionen anzubieten, diese Sammlungen zu teilen. So entstand dabei nebenbei das Social Bookmarking. Damit wurde es aber notwendig, dass etwas mehr Informationen erfasst wurden als nur der Link und der Titel.
So konnten die Einträge um Zusammenfassungen, Kategorien, Kommentare und Bewertungen erweitert werden. Manche Services erlaubten es sogar, bestimmte Lesezeichen-Kategorien als RSS-Feed zu abonnieren, um die Community über neue und populäre Links zu einem Thema zeitnah zu informieren.
Dieser Aspekt des Social Bookmarkings führt direkt zur zweiten Art des Speicherns: der Anreicherung von Links mit Metadaten.
2. Bookmarks mit Metadaten
Ein Lesezeichen, das nur aus URL und Titel besteht, eignet sich vor allem für Linklisten in der Favoritenleiste oder auf einer privaten Startseite, um häufig besuchte Seiten schnell aufzurufen, wie diesen Guide, Zeitungen oder Web-Apps. Für alles andere fehlt nach ein paar Wochen oft der Kontext, warum diese Seite überhaupt gespeichert wurde. Und selbst wenn man sich noch erinnert, kann der Inhalt hinter der URL inzwischen ein ganz anderer sein.
Praktisch alle aktuellen Bookmark-Services bieten Browser-Erweiterungen, mit denen eine Webseite schnell online abgelegt und mit einem erweiterten Set an Metadaten versehen werden kann, teilweise sogar automatisch. Das erleichtert die Verwaltung, schafft aber gleichzeitig eine Abhängigkeit vom jeweiligen Anbieter. Das ist besonders ärgerlich, wenn solche Services wie Delicious (2019), Omnivore (2024) und zuletzt Pocket (2025) eingestellt werden.
Nach dem Shutdown von Omnivore habe ich mir eine lokale Lösung gebaut, mit der ich Lesezeichen, Vorschaubilder und Tags direkt in Obsidian speichern kann und so unabhängig von externen Anbietern bleibe. Wie diese Lösung mit dem Obsidian Web Clipper implementiert werden kann, zeige ich dir weiter unten.
3. Bookmarks mit Inhalten
In der nächsten Stufe wird dem Lesezeichen noch mehr Kontext mitgegeben. So werden neben den meist automatisch erstellten Metadaten auch konkrete Textauszüge, Tags und eigene Notizen hinzugefügt. Dieses Vorgehen erzwingt eine erste aktive Auseinandersetzung mit den Inhalten und ist damit der eigentliche Beginn der Wissensarbeit. Auch hierzu habe ich in meinem Blog eine eigene Lösung vorgestellt: Erfassung ausgewählter Bereiche in Web-Browsern für Obsidian. Diese Lösung habe ich inzwischen mit dem Obsidian Web Clipper neu umgesetzt.
4. Speichern ganzer Webseiten
Diese bisher vorgestellten Lösungen haben aber einen Haken: Der vollständige Inhalt des Artikels ist nicht mehr zugänglich, sobald der Link nicht mehr erreichbar ist, weil sich der Inhalt der URL geändert hat oder der Webserver nicht mehr existiert. Es besteht zwar oft die Chance, dass die Wayback Machine des Internet Archive die Seite archiviert hat, aber es ist oft sinnvoller, zumindest wichtige Inhalte dauerhaft selbst zu speichern. Auch für diesen Ansatz gibt es Anbieter von Web-Anwendungen, die neben Links und Metadaten auch die gesamte Seite speichern. Dabei wird die Webseite meist nicht 1:1 gespeichert, sondern zunächst bereinigt: Werbung, Navigation, Kommentarbereiche und anderer Ballast werden entfernt, sodass nur der eigentliche Artikelinhalt abgelegt wird.
Für diese Entschlackung von Webseiten auf das Wesentliche wurden einige Programmierbibliotheken entwickelt. Lange Zeit war Mozilla Readability der de-facto-Standard, der auch den Reader-Ansichten in Firefox und Safari zugrunde liegt. Readability arbeitet dabei rein heuristisch, d.h. es analysiert die DOM-Struktur einer Seite und versucht anhand der Textdichte, Elementgröße und CSS-Klassen zu erraten, was der Hauptinhalt ist. Das funktioniert für viele Seiten gut genug, scheitert aber regelmäßig an JavaScript-gerenderten Inhalten oder spezialisierten Plattformen.
Mit der Programmierbibliothek Defuddle wurde dieser Ansatz erweitert. Und nicht nur das: Die Bibliothek wurde vom Obsidian-Team selbst entwickelt und ist daher gezielt auf die Erstellung von Markdown für Obsidian ausgerichtet.
Defuddle verfolgt bei der Analyse einer Webseite einen zweigleisigen Ansatz. Für unbekannte Seiten arbeitet es ebenfalls heuristisch, bezieht dabei aber zusätzlich die mobilen Stylesheets einer Seite ein. Die Idee dahinter ist, dass Elemente, die auf kleinen Bildschirmen ausgeblendet werden, also etwa Navigation oder Werbung, selten zum eigentlichen Inhalt gehören.
Für bekannte Plattformen wie Reddit, Youtube, Hacker News, Twitter oder ChatGPT greift Defuddle auf eingebaute seitenspezifische Erkennungsregeln zurück, die genau wissen, wo der relevante Inhalt im DOM zu finden ist, ohne raten zu müssen. Zusätzlich sorgt Defuddle dafür, dass bestimmte Inhaltselemente wie Code-Blöcke, mathematische Formeln und Fußnoten immer in einer einheitlichen Form im Ergebnis landen, unabhängig davon wie die jeweilige Webseite sie ursprünglich dargestellt hat. Das erleichtert die spätere Weiterverarbeitung in Obsidian erheblich.
Außerdem liest Defuddle strukturierte Metadaten aus, die viele Webseiten unsichtbar im Hintergrund mitliefern. Verlage, Blogs und Nachrichtenportale hinterlegen dort maschinenlesbare Angaben zu Autor, Erscheinungsdatum, Kategorie oder Schlagworten, vor allem weil Suchmaschinen wie Google diese Daten für ihre Suchergebnisse auswerten. Defuddle macht sich das zunutze und kann diese Angaben als Properties in Obsidian verfügbar machen, ohne dass du sie manuell eintippen musst.
Der Obsidian Web Clipper nutzt Defuddle im Hintergrund, um Webseiten zu verarbeiten. Was dabei im Vault landet, ist kein roher HTML-Dump, sondern sauber aufbereitetes Markdown mit automatisch befüllten Properties.
Vom Sammeln zum Verstehen
Diese beschriebenen vier Stufen des Speicherns von Lesezeichen sind keine Hierarchie, bei der die letzte immer die beste ist. Es kommt auf den Workflow an. Fil Salustri beschreibt in seinem Artikel My Obsidian Clipper Bookmarking Templates: 2026 Edition einen Workflow, den ich auch nutze und der drei Phasen unterscheidet. Interessanterweise nutzt er dafür medizinische Begriffe, die die Phasen aber treffend beschreiben.
- Die erste Phase ist die Intake (Aufnahme): Die Fundstelle landet zunächst ohne weitere Bewertung oder Einordnung in einem Stapel.
- In der zweiten Phase, der Triage (Auswahl), wird eine Fundstelle aus dem Stapel herausgeholt und aktiv bewertet: Warum ist das relevant? Wo und wie soll es verwendet werden? Hier kann eine erste Notiz entstehen, die diese Entscheidungen festhält. Hier beginnt die eigentliche Auseinandersetzung mit dem Inhalt. Die Bewertung kann aber auch negativ ausfallen und das Lesezeichen kann dann gelöscht werden.
- Die dritte Phase, das Treatment (Verarbeitung), bezeichnet dann den Schritt, in dem die Quelle schließlich in den eigenen Wissenskontext eingebettet wird. Sie wird zitiert, verknüpft, weitergedacht. Dieser Schritt kann Minuten oder Wochen dauern und bringt oft eine ganze Reihe neuer Gedanken und Notizen mit sich, die ihrerseits wieder behandelt werden wollen.
Dieses Modell erklärt auch, warum Read-it-Later-Dienste so oft scheitern: Sie optimieren für den „Intake”, aber „Triage” und „Treatment” finden nie statt. Der Stapel wächst, die Auseinandersetzung bleibt aus.
Hier kann der Obsidian Web Clipper helfen. Er ist nicht nur ein Werkzeug zum Speichern von Fundstellen, sondern unterstützt auch das strukturierte Erfassen, mit Properties, Vorlagen und der Möglichkeit, Inhalte direkt in den eigenen Wissenskontext einzubetten. Wie das konkret funktioniert, zeigen die folgenden Abschnitte.
Obsidian Web Clipper
Der Obsidian Web Clipper ist keine Obsidian-Erweiterung, sondern eine Browser-Erweiterung für Chrome, Safari, Firefox, Edge und weitere Browser. Er läuft auf allen Plattformen, auf denen auch Obsidian läuft. Obsidian ist zwar nicht zwingend notwendig, die geclippten Inhalte können auch als Dateien gespeichert werden, sein volles Potential spielt der Web Clipper aber nur mit Obsidian aus.
Ein guter Startpunkt ist die offizielle Obsidian Web Clipper Seite (hier unter macOS im Brave Browser):
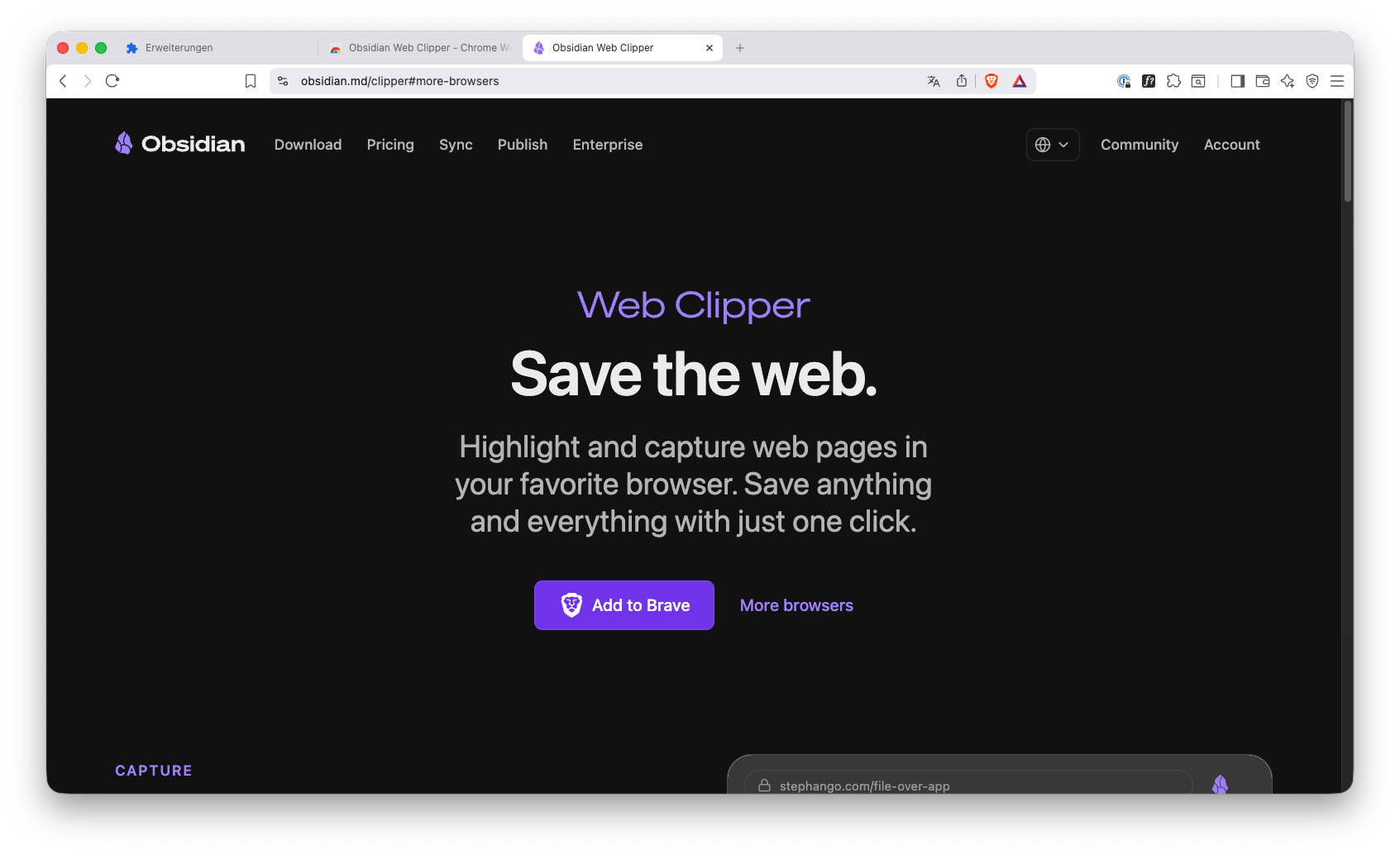
Auf dieser Seite sind alle unterstützten Browser mit Links zu den jeweiligen Stores aufgelistet. Im Falle von Brave wirst du auf den Chrome Web Store geleitet.
Wenn die Browser-Erweiterung installiert und aktiviert ist, kannst du sie direkt aufrufen und die erste Webseite in deinen Vault clippen, wobei ohne weitere Konfiguration der zuletzt aktive Vault genutzt wird.
So wird dann z.B. aus der Einstiegsseite des ObsidianGuides im Web:
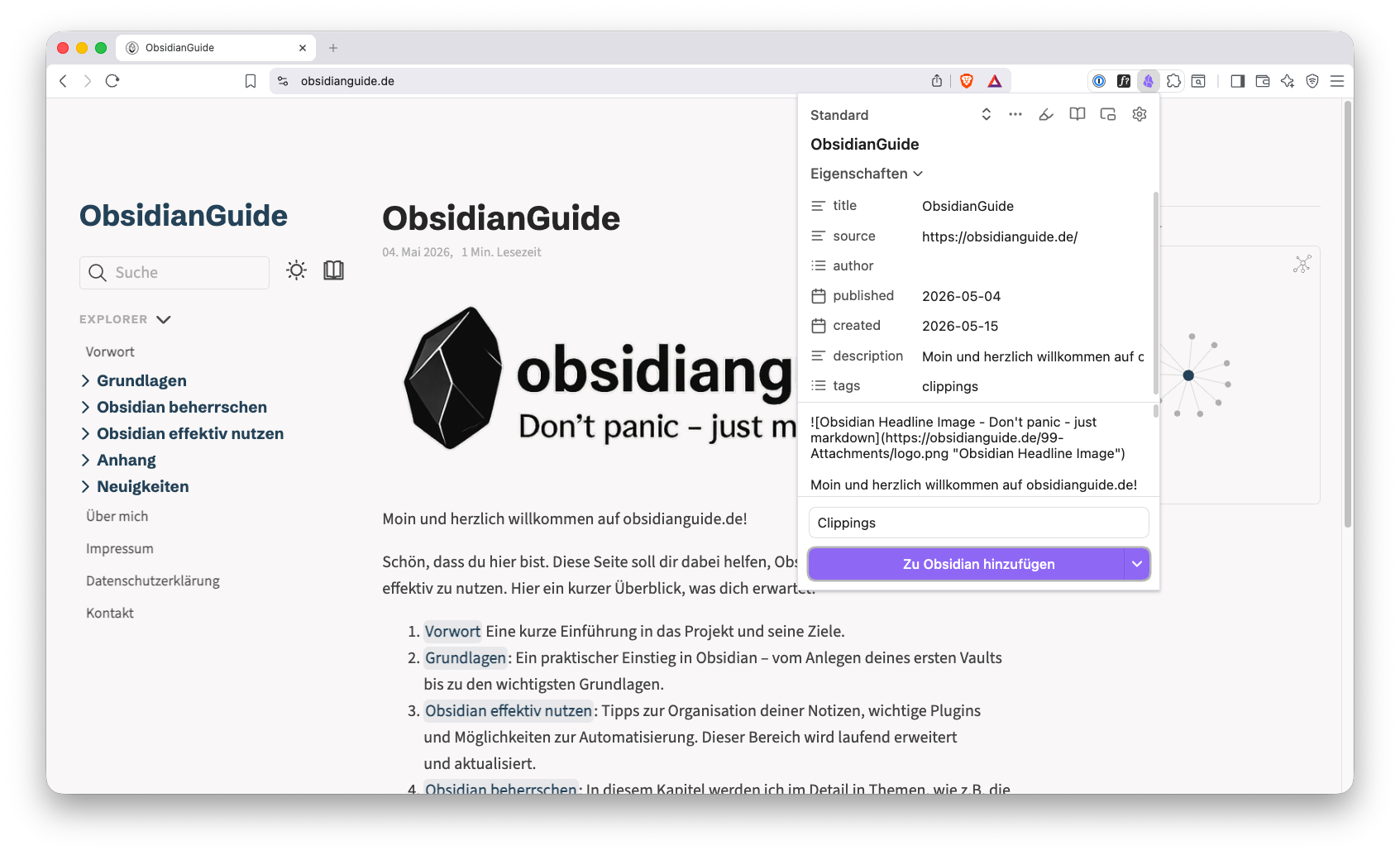
Eine Notiz in deinem Vault:
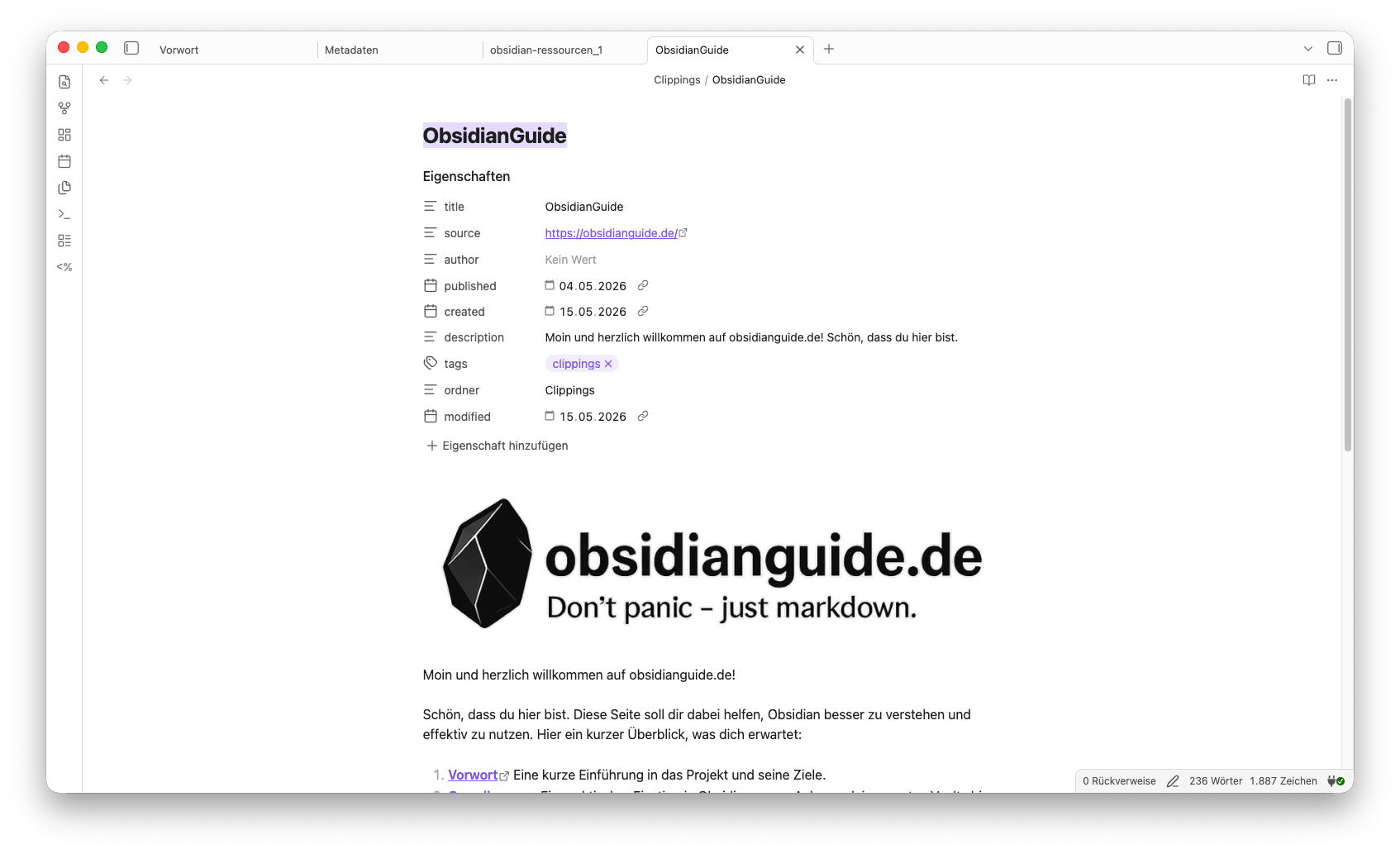
Obsidian Web Clipper Vorlagen
Nun hast du schon eine Webseite als Notiz in Obsidian geclippt. Aber der Web Clipper kann mehr, als den Inhalt einer Seite einfach in den Vault zu kopieren. Mit Vorlagen lässt sich genau steuern, was geclippt wird, in welchem Format und mit welchen Properties. Die folgenden Beispiele orientieren sich dabei an den vier Stufen aus der Einleitung, von der einfachen Lesezeichenliste bis zur vollständigen Seite.
Die einfache Bookmark-Liste
Im ersten Beispiel wird eine Notiz mit einfachen Bookmarks gefüllt, bestehend aus dem Webseiten-Titel, dem Link und der Domain:
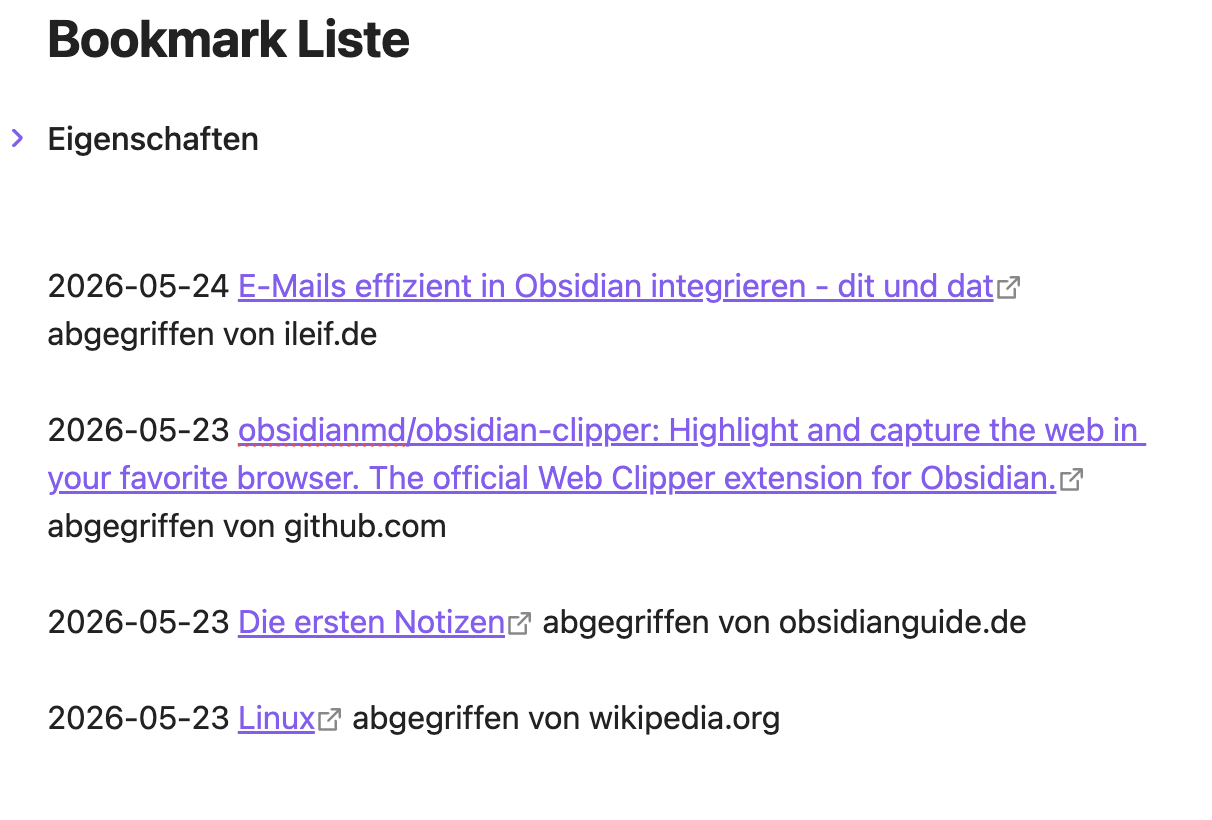
Als erstes erstellst du eine neue Notiz und gibst ihr einen Namen, der den Zweck beschreibt. Du kannst die Notiz mit den in deinem Vault üblichen Eigenschaften versehen und in einem passenden Ordner ablegen. In diesem Beispiel heißt die Notiz Bookmark Liste und liegt im Ordner Bookmarks.
Nun öffne den Browser und klicke auf das Obsidian Web Clipper Icon:
Der Einstellungsdialog öffnet sich als ein neues Browser-Tab.
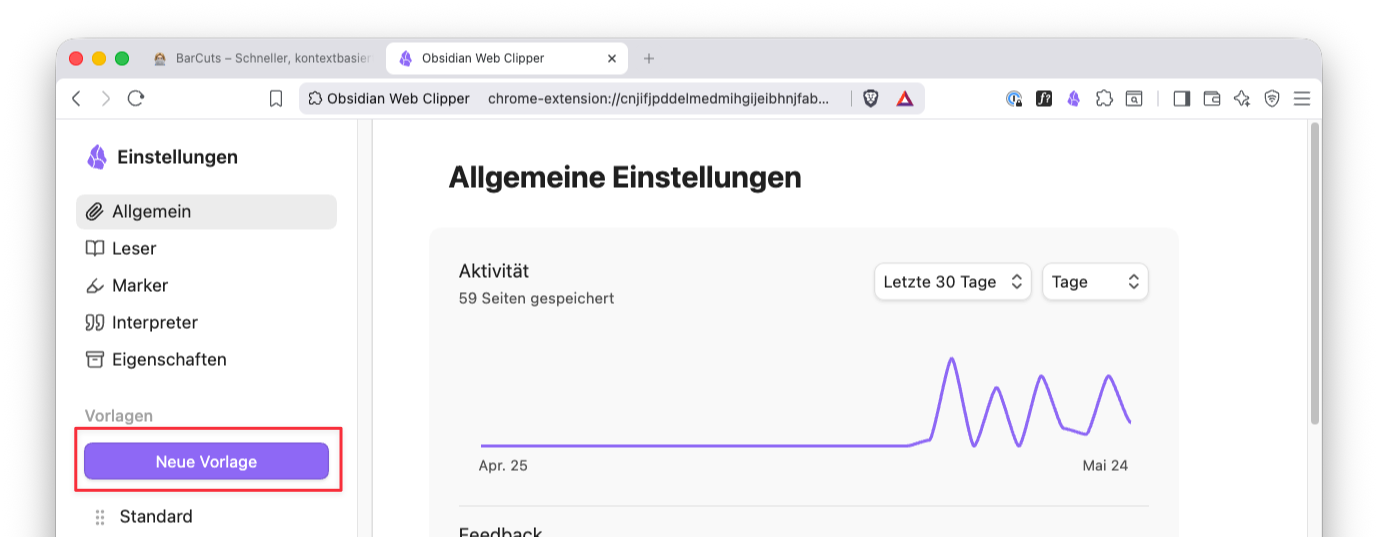
Im linken Side-Panel klicke auf den Button „Neue Vorlage”. Im rechten Bereich öffnet sich dann die Ansicht „Vorlage bearbeiten”, in der du alle Einstellungen vornehmen kannst:
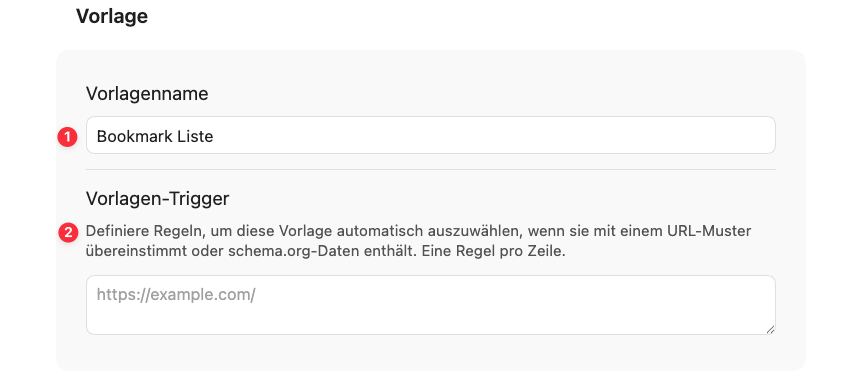
In dem Feld (1) gibst du den Namen der Vorlage ein. Der Name wird relevant, sobald du mehrere Vorlagen verwendest und beim Clippen einer Webseite zwischen ihnen wählen kannst.
Mit dem Vorlagen-Trigger in Feld (2) lässt sich eine Vorlage automatisch für bestimmte Webseiten vorauswählen, etwa wenn du für eine bestimmte Seite immer eine andere Vorlage als die Standardvorlage verwenden möchtest. Da diese Vorlage auf allen Webseiten funktionieren soll, bleibt das Feld leer. Die graue URL dient nur als Beispiel und stellt keine Eingabe dar.
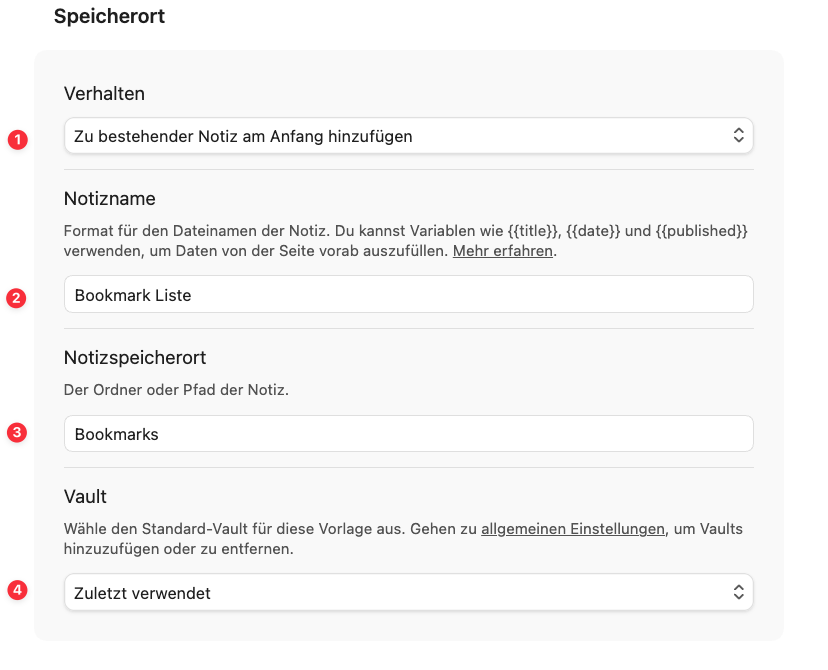
Als nächstes wählst du unter „Verhalten” die Option „Zu einer bestehenden Notiz am Anfang hinzufügen” aus, da in unserem Fall keine neue Notiz erstellt werden soll.
Weitere Optionen wären:

Im Feld „Notizname“ (2) trägst du dann „Bookmarkliste“ als Namen der Notiz ein, in der das Ergebnis gespeichert werden soll.
Falls die Notiz noch nicht existiert, wird sie beim ersten Clippen automatisch erstellt. Das gilt auch dann, wenn du dich beim Namen vertippst. Dasselbe gilt für den „Notizspeicherort” (3).
Wenn du mit mehreren Vaults arbeitest, kannst du hier einen Vault aus der Liste auswählen, die du in den Obsidian Web Clipper Einstellungen eingetragen hast. Mit der Einstellung „Zuletzt verwendet” wird der zuletzt aktive Vault genutzt, auch wenn Obsidian im Moment des Clippens nicht geöffnet ist.”
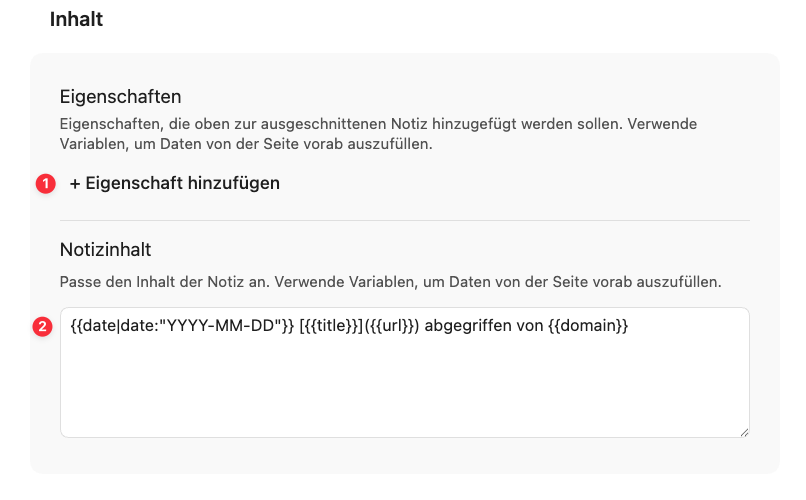
Wenn der Web Clipper eine neue Notiz erstellt, kannst du im Abschnitt „Eigenschaften” (1) die Properties festlegen, die der Notiz als Frontmatter hinzugefügt werden. In unserem Fall sollte hier keine Eigenschaft definiert sein, da das Ergebnis zu einer bestehenden Notiz hinzugefügt wird.
Im nächsten Abschnitt wird der „Notizinhalt“ (2) definiert. Dafür stehen dir Variablen zur Verfügung, die beim Clippen automatisch mit den aktuellen Werten der geclippten Seite befüllt werden, sowie normaler Text und Markdown-Auszeichnungen.
Für dieses Beispiel verwendest du folgende Standardvariablen:
datefür das aktuelle Datumtitlefür den Titel der Webseiteurlfür den Linkdomainfür die Quell-Domain”
Da die date-Variable den Wert 2026-05-25T01:39:21+02:00 zurückgibt, solltest du dieses Ergebnis noch formatieren. In diesem Beispiel wird das Datum der besseren Lesbarkeit halber in das Format 2026-05-25 umgewandelt.
Dazu setzt du einen sogenannten Filter ein. Filter sind Funktionen, die den Wert einer Variable entgegennehmen, verarbeiten und das Ergebnis zurückgeben. Wer mit der Unix-Kommandozeile vertraut ist, kann sich Filter wie Pipes vorstellen: Der Wert fließt von links nach rechts durch eine Kette von Verarbeitungsschritten. Für die Datumsformatierung verwendest du den Filter date:, der das Datum entsprechend der Definition der Day.js-Bibliothek umwandelt:
{{date|date:"YYYY-MM-DD"}}
Es folgt der Titel als klickbarer Link in der Markdown-Syntax für externe Links:
[{{title}}]({{url}})
Da die URL nicht mehr sichtbar ist, wird die Zeile noch um einen kurzen Hinweis und die Domain ergänzt, die in der Variable {{domain}} gespeichert ist. So ergibt als Eingabe in das Feld Notizinhalt
{{date|date:"YYYY-MM-DD"}} [{{title}}]({{url}}) abgegriffen von {{domain}}
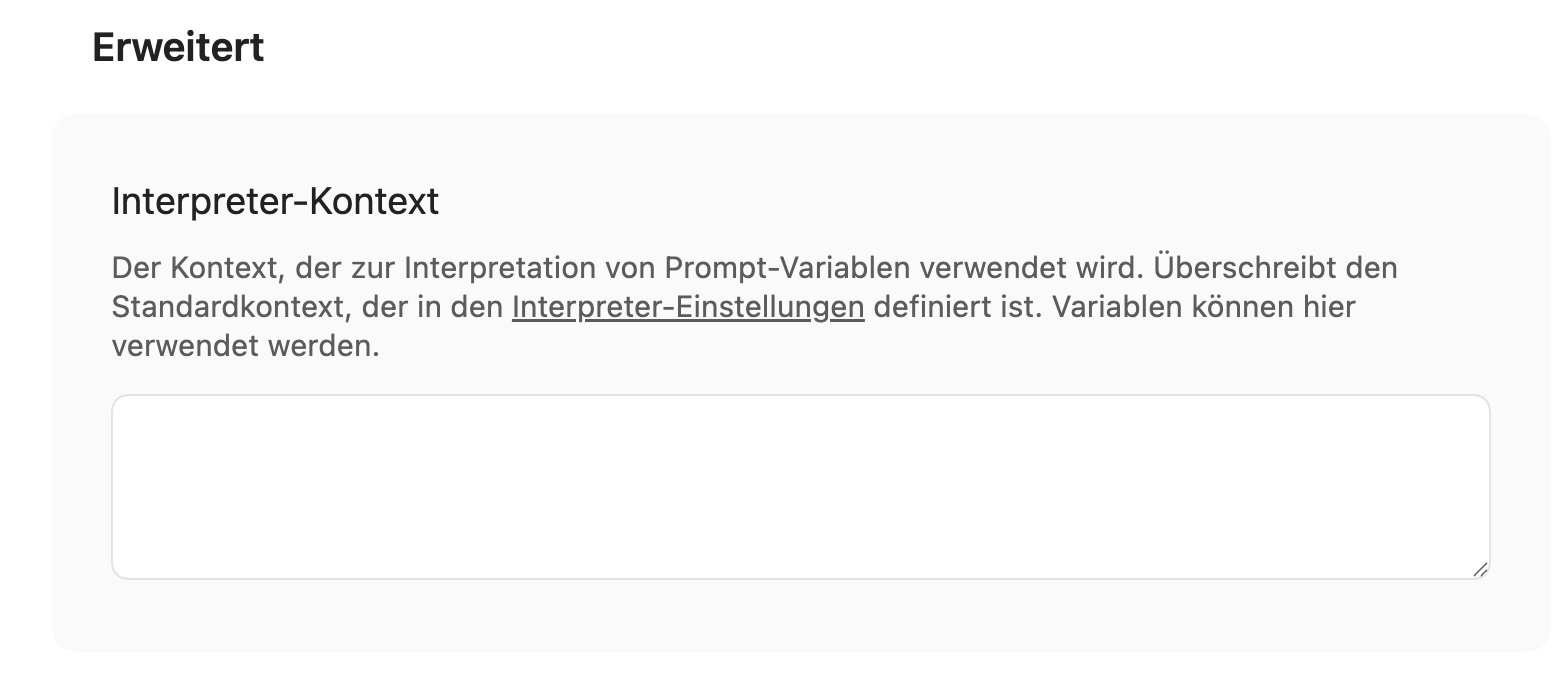
Im letzten Bereich „Erweitert” lässt sich ein bestimmter Kontext für die Auswertung von Webseiteninhalten durch eine KI beschreiben. Für das Beispiel einer einfachen Bookmark-Liste bleibt das Feld leer.
Zusammenfassung
Dieses Beispiel zeigt, dass der Obsidian Web Clipper weit mehr kann als ganze Webseiten in Notizen umzuwandeln.
Das zentrale Konzept sind die Variablen. Defuddle zieht beim Clippen Informationen aus einer Webseite heraus und legt sie in Variablen wie title, url, domain oder date ab. Diese Variablen kannst du frei kombinieren, um daraus eine einzelne Zeile zu bauen wie in diesem Beispiel, aber auch komplexe Notizstrukturen mit Properties, Abschnitten und Inhalten zu füllen.
Mit Filtern lassen sich die Rohwerte dieser Variablen weiter verarbeiten, etwa ein Datum in ein anderes Format bringen oder Text kürzen.
Das Verhalten bestimmt schließlich, was mit dem Ergebnis passiert: ob eine neue Notiz erstellt oder eine bestehende ergänzt wird. Wir haben hier nur eine von mehreren Optionen kennengelernt.
Lesezeichen mit Preview
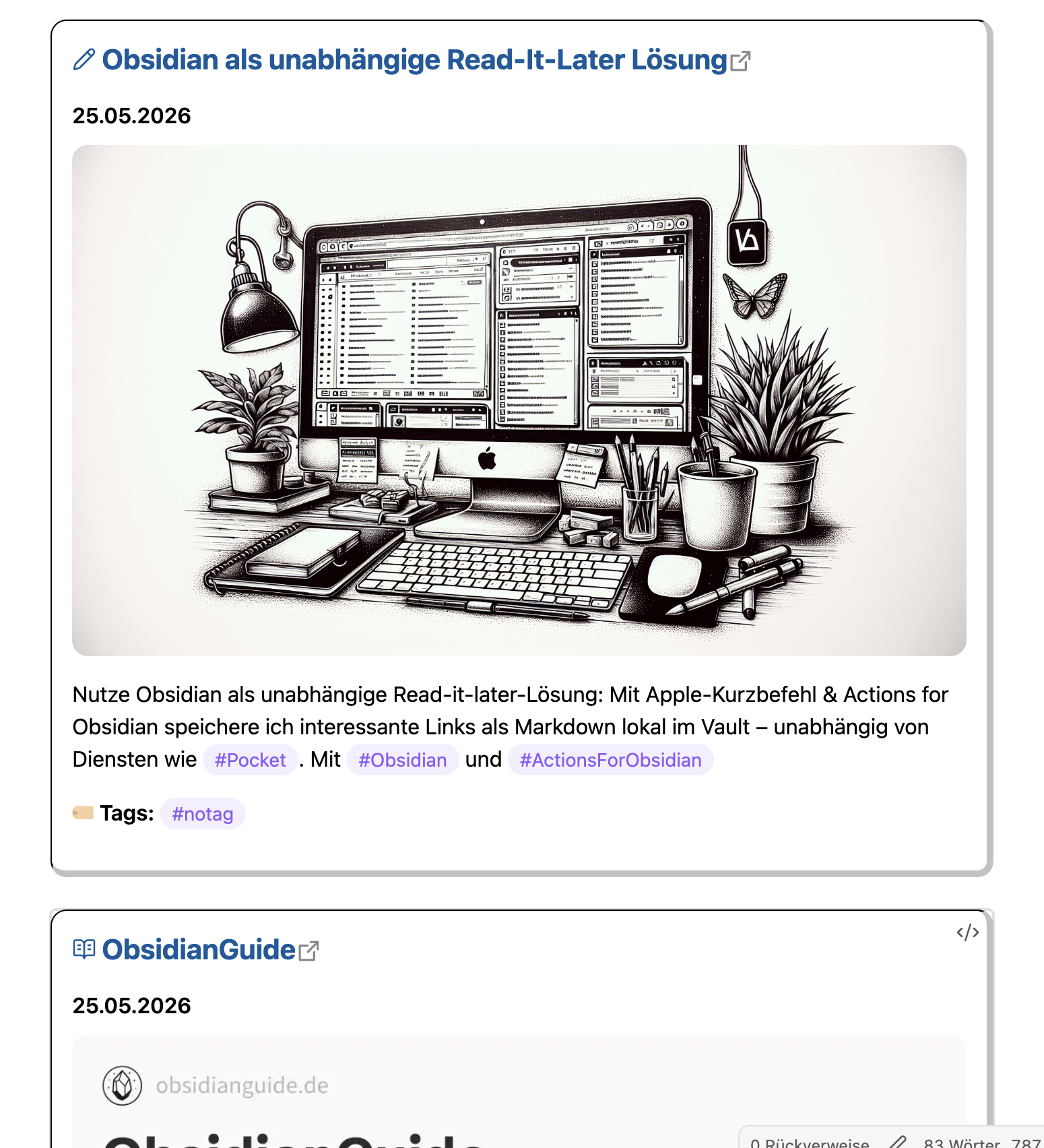
Als nächstes Beispiel wird der Bookmark neben Datum und Link auch noch mit einem Vorschaubild und einer Beschreibung der Webseite versehen. Viele Webseiten hinterlegen beides als Metadaten, das Bild etwa als og:image und die Beschreibung als description. Defuddle liest diese Metadaten beim Clippen automatisch aus und stellt sie als Variablen zur Verfügung.
Zusätzlich wird eine Zeile erstellt, in der du zu jedem Bookmark Tags hinzufügen kannst. Diese Tags kannst du in Obsidian zum Beispiel nutzen, um Bookmarks schnell zu finden.
Auch diese Clips werden in einer Notiz gespeichert, allerdings visuell etwas aufbereitet. Dazu wirst du ein CSS-Snippet erstellen.
Für dieses Beispiel legst du zunächst eine neue leere Notiz mit dem Namen Bookmark mit Preview im Ordner Bookmarks an.
Nun erstellst du, wie oben beschrieben, eine neue Vorlage ein. Die Einstellungen sind fast identisch mit den vorherigen:
- Vorlagenname:
Bookmark Preview - Verhalten:
Zu bestehender Notiz am Anfang hinzufügen - Notizname:
Bookmark mit Preview - Notizspeicherort:
Zuletzt verwendetoder der Name deines Vaults - Keine Eigenschaften, falls hier welche angegeben sind, lösche sie
Der Notizinhalt ist in diesem Beispiel etwas komplexer:
> [!bookmark] **[{{title|safe_name}}]({{url}}) **
>
> **{{date|date:"DD.MM.YYYY"}}**
{% if image %}
> 
{% endif %} >
>
> {{description}}
>
> 🏷️ **Tags:** #notag
Für die Darstellung als Karte verwendest du ein Callout, daher das > vor jeder Zeile. Den Callout-Typ bookmark ist kein vordefinierter Obsidian-Typ, sondern einer den du selbst definierst. Wie das geht, zeige ich weiter unten.
Mit **[{{title|safe_name}}]({{url}})** wird der Titel der Webseite als fett formatierter, klickbarer Link ausgegeben. Das geschieht über die normale Markdown-Link-Syntax [name](url), wobei der Name aus der Variable title stammt. Der Filter safe_name sorgt dabei dafür, dass keine Zeichen im Titel landen, die in Dateinamen nicht erlaubt sind, etwa : unter macOS. Für eine einfache Bookmark-Liste ist das weniger kritisch, aber es ist eine gute Gewohnheit, diesen Filter grundsätzlich auf Titel anzuwenden.
Als nächstes wird das aktuelle Datum ausgegeben: > **{{date|date:"DD.MM.YYYY"}}**. Der Filter bringt das Datum in das im deutschsprachigen Raum gebräuchliche Format. Auch diese Zeile wird fett ausgegeben.
In den nächsten Zeilen wird eine Bedingung genutzt:
{% if image %}
> 
{% endif %} >
Mit {% if image %} wird das Vorschaubild nur dann ausgegeben, wenn die Webseite ein entsprechendes Bild in ihren Metadaten hinterlegt hat. Fehlt dieses Bild, würde ohne die Bedingung ein leerer Bild-Platzhalter erscheinen. Das > hinter {% endif %} ist nötig, weil die Bedingung im generierten Markdown eine Leerzeile erzeugt, die den Callout sonst unterbrechen würde.
Es folgt die Variable {{description}}, die ebenfalls einem Metadatum im HTML entspricht und nicht auf jeder Webseite vorhanden ist. Fehlt sie, wird nur das > ins Ergebnis geschrieben, was lediglich eine leere Callout-Zeile erzeugt, aber keinen Platzhalter oder Fehler.
In der letzen Zeile kannst du manuell später einen oder mehrere Tags eintragen. Vorgegeben ist #notag, womit sich diese Bookmarks über die Suche in Obsidian leicht finden lassen.
Wenn du den Web Clipper jetzt mit dieser Vorlage auf einer Webseite aufrufst, wird das Ergebnis noch sehr schlicht aussehen. Damit der Bookmark wie im Screenshot oben dargestellt wird, muss Obsidian noch wissen, wie ein bookmark-Callout aussehen soll.
Dazu bietet Obsidian die CSS-Snippets. Unter Einstellungen CSS Snippets findest du Hinweise, wie du ein solches Snippet ablegen kannst.
Das folgende CSS kannst du zum Beispiel in einer neuen Datei mit dem Namen bookmark.css in deinem Snippet-Ordner im .obsidian-Einstellungsordner speichern. Der Dateiname ist dabei beliebig, aber die Definition callout[data-callout="bookmark"] muss den richtigen Callout-Namen enthalten.
/* Callout mit weißem Hintergrund und blauer Seitenlinie */
.callout[data-callout="bookmark"] {
--callout-color: white;
--callout-icon: book-open-text;
}
.callout[data-callout="bookmark"] {
background: white !important; /* Weißer Hintergrund */
border: 1px solid black;
border-right: 5px solid #6666 !important; /* Blaue Seitenlinie */
border-bottom: 5px solid #6666 !important; /* Blaue Seitenlinie */
border-radius: 12px; /* Abgerundete Ecken */
padding: 15px;
}
/* Anpassung der Titel-Farbe */
.callout[data-callout="bookmark"] .callout-title {
font-weight: bold;
color: #005a9c;
font-size: 1.3em;
}
/* Entfernen der Unterstreichung für Links im Titel */
.callout[data-callout="bookmark"] .callout-title a {
text-decoration: none !important; /* Keine Unterstreichung */
color: #005a9c;
font-weight: bold;
}
.callout[data-callout="bookmark"] .callout-title a:hover {
text-decoration: none !important;
color: #003366; /* Dunkleres Blau beim Hover */
}
/* Sicherstellen, dass der Text in dunklen Themes lesbar bleibt */
.callout[data-callout="bookmark"] p {
color: black !important;
}
/* Bilder in Callouts */
.callout[data-callout="bookmark"] img {
max-width: 100%;
height: auto;
border-radius: 12px;
margin-top: 10px;
display: block;
}
Nachdem das Snippet gespeichert und aktiviert wurde, sollte der Bookmark in Obsidian entsprechend dargestellt werden.
Zusammenfassung
Dieses Beispiel führt zwei neue Konzepte ein. Erstens die Bedingungslogik mit {% if %}: Der Web Clipper kann auf das Vorhandensein bestimmter Variablen reagieren und den generierten Inhalt entsprechend anpassen. Zweitens die CSS-Snippets: Obsidian lässt sich durch eigene Stylesheet-Definitionen erweitern, was hier genutzt wird, um einen neuen Callout-Typ bookmark mit eigenem Aussehen zu definieren. Beide Konzepte zusammen ermöglichen es, aus einem einfachen Web-Clip eine visuell ansprechende und einheitlich formatierte Karte zu machen.
Die Standard-Vorlage
Bevor du weitere eigene Vorlagen erstellst, lohnt sich ein genauerer Blick auf die mitgelieferte Standard-Vorlage. Sie ist ein guter Ausgangspunkt, um eigene Vorlagen zu entwickeln.
Die Standard-Vorlage lässt sich jederzeit auf den [Auslieferungszustand](02 Obsidian Web Clipper - Einstellungen#Standardvorlage zurücksetzen (10)) zurücksetzen, umbenennen und vor allem durch Duplizieren als Basis für eigene Vorlagen nutzen.
Einstellungen der Standard-Vorlage
Vorlagenname: Den Namen der Vorlage kannst du frei ändern. Wenn du die Standard-Vorlage danach zurücksetzt, wird die umbenannte Vorlage nicht ersetzt, sondern eine neue Standard-Vorlage angelegt. Dabei werden leider die Definitionen der Eigenschaften aus den [Einstellungen](02 Obsidian Web Clipper - Einstellungen#Eigenschaften) nicht übernommen (Web Clipper Version 1.6.1).
Der Begriff „Standard-” oder „Default-Vorlage” ist etwas irreführend. Gemeint ist die Vorlage, die automatisch verwendet wird, wenn du direkt auf „Zu Obsidian hinzufügen” klickst. Das wird nicht durch einen besonderen Status bestimmt, sondern schlicht durch die Position in der Liste. Im Beispiel unten ist Bookmark Preview diese Vorlage. Die Reihenfolge lässt sich ändern, indem du einen Eintrag am Anfasser (1) an die gewünschte Position ziehst.
Auch wird eine neue Vorlage nicht auf Basis der Standard-Vorlage erstellt, sondern beginnt immer leer. Standard bedeutet hier nur, dass sie mitgeliefert wird und zurücksetzbar ist.
Vorlagen-Trigger: Da diese Vorlage für alle Webseiten gelten soll, bleibt das Feld leer. Falls du spezifische Vorlagen für bestimmte Webseiten verwendest kannst du hier die URL eingeben.
Verhalten: In diesem Fall wird eine neue Notiz erstellt.
Notizname: Hier ist die erste Anpassung nötig. Im Auslieferungszustand steht hier nur {{title}}, was dazu führen kann, dass der Titel Sonderzeichen enthält, die als Dateiname nicht erlaubt sind. Der Filter safe_name behebt das. Ändere den Inhalt daher zu: {{title|safe_name}}.
Notizspeicherort: Hier kannst du einen Ordner festlegen, in dem alle Clippings mit dieser Vorlage gespeichert werden. Vorgegeben ist Clippings, der Name lässt sich aber ändern.
Vault: Vorgegeben ist „Zuletzt verwendet”, also der Vault der gerade aktiv bearbeitet wird oder der zuletzt aktive Vault, falls Obsidian nicht geöffnet ist. Du kannst aber in den Einstellungen deinen Vaults eintragen, die du dann hier ggf einstellen kannst.
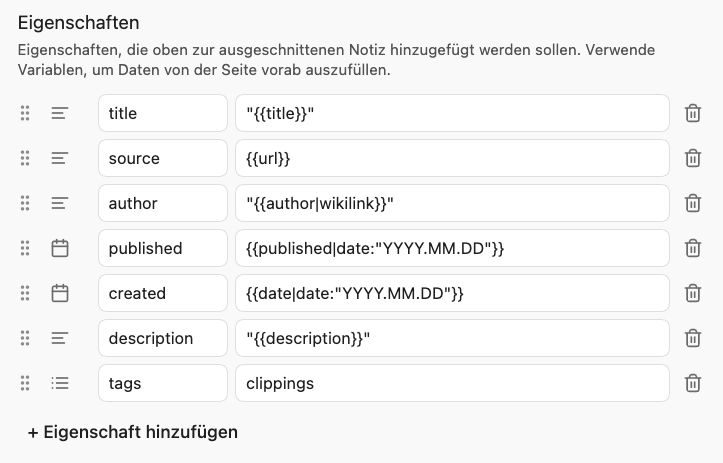
Eigenschaften: Hier werden die Eigenschaften definiert, die in der Notiz als Frontmatter verwendet werden sollen. Du kannst die Eigenschaftsnamen frei wählen. So wirst du vielleicht statt created in deinem Vault eher erstellt nutzen. Der Wert, also die Variable, bleibt in beiden Fällen {{date}}.
Hier einige empfohlene Anpassungen (originaler Eigenschaftsname → Änderung):
-
title → titel: Wie schon beim Dateinamen erwähnt, kann der Titel Sonderzeichen enthalten, die auch in den Eigenschaften einer Notiz Probleme machen. Um sicherzugehen, kannst du statt des Filters
safe_name, der diese Zeichen entfernt, die Variable{{title}}in Anführungszeichen setzen:"{{title}}". Damit ist meistens sichergestellt, dass der Titel an dann im Markdownteil der Notiz alle Sonderzeichen erhalten bleiben. -
source → quelle: Den Eintrag kannst du so lassen. Die URL wird als klickbarer Wert eingetragen.
-
author → autor: Die Variable
{{author}}liefert bei Artikeln mit mehreren Autoren manchmal eine kommagetrennte Liste wieMax Mustermann, Erika Musterfrau. Mit einer Filterkette lässt sich daraus eine Liste von Wikilinks machen:{{author|split:", "|wikilink|join}}Die Idee dahinter:
split:", "zerlegt den String an jedem Komma in einzelne Werte,wikilinkwandelt jeden davon in einen Wikilink um, undjoinfügt sie wieder zusammen. -
published → erschienen: Falls ein entsprechendes Metadatum vorhanden ist, wird es über die Variable
{{published}}gespeichert. Wenn du die Eigenschaftpublishedodererschienenin der type.json bereits alsdatetypisiert hast, wird das Datum in Obsidian zwar mit einer Kalender-Eingabehilfe angezeigt, im Markdown-Quellcode steht dann aber ein Wert wie2021-04-26T06:59:33Z. Ich habe mir angewöhnt Eigenschaften mit Datumsangaben immer auf die Uhrzeit und die Zeitzone zu verzichten und setzte hier und als FormatYYYY-MM-DDzuverwnden, das du mit dem Filter so erzeugst:{{published|date:"YYYY-MM-DD"}}. -
created → erstellt: Für diese Eigenschaft wird die Variable
{{date}}genutzt, die das aktuelle Datum enthält. Auch hier nutze ich den Filter:{{date|date:"YYYY-MM-DD"}}. -
description → beschreibung: Falls der Web Clipper eine Beschreibung auf der Webseite findet, wird sie in der Variable
{{description}}gespeichert. Wie beim Titel kann ein:in der Beschreibung Probleme verursachen, daher auch hier die Variable in Anführungszeichen setzen:"{{description}}". Allerdings bleibt bei dieser Lösung das Problem bestehen, falls ein Beschreibung ein"enthält. Das ist dann eine Abwägung die du treffen mußt, ob du ab und zu mal einen Fehler manuell fixen musst oder Auf einige sinnvolle Sonderzeichen wie?in einer Beschreibung in den Eigenschaften verzichten willst.
Somit sollten die Eigenschaften so aussehen:
Nun werden noch zwei weitere mögliche Einstellungen angezeigt. Den „Interpreter-Kontext” wirst du in einem späteren Abschnitt kennenlernen. Hier schauen wir uns zunächst nur den „Notizinhalt” an.
In diesem Feld legst du fest, wie die Notiz aussehen soll, die mit dieser Vorlage erstellt wird. In der Standard-Vorlage ist nur {{content}} eingetragen. Mit dieser Variable wird der Inhalt der Webseite als Markdown in die neu erstellte Notiz übertragen. Du kannst aber auch Text, Markdown oder HTML mit Variablen mischen, wie im Bookmarks mit Preview-Beispiel gezeigt.
Unterstützung für spezielle Webseiten
Die Standard-Vorlage bietet auch für spezielle Webseiten wie YouTube, Reddit, Hacker News oder ChatGPT eine optimierte Auswertung, sowohl beim Clippen als auch im Lesemodus. Bei diesen Webseiten lässt sich der browsereigene Lesemodus meist gar nicht aktivieren.
Für YouTube zeigt der Lesemodus das Video und das Transkript an, das automatisch mitscrollen kann und auch zur Navigation innerhalb des Videos genutzt werden kann. Die geclippte Notiz enthält das eingebettete Video, den Begleittext und das Transkript.
Für Reddit werden die Kommentare sauber dargestellt. Im Lesemodus werden die Autoren der Kommentare zusätzlich farblich unterschieden.
Eine ChatGPT-Unterhaltung wird sauber formatiert und im Lesemodus wird ein Navigationspanel angezeigt.
Für Hacker News ermöglicht der Obsidian Web Clipper überhaupt erst einen Lesemodus, bei dem ein Klick auf eine Meldung den Lesemodus nicht verlässt.
Zusammenfassung
Die Standard-Vorlage ist mehr als ein einfaches Starterset. Sie zeigt das volle Spektrum dessen, was der Web Clipper leisten kann. Dazu gehören strukturierte Eigenschaften mit angepassten Namen und Formaten, Variablen mit Filtern für sichere Dateinamen und korrekte Datumsformate sowie die {{content}}-Variable, die den Seiteninhalt direkt als Markdown übernimmt.
Für spezielle Plattformen wie YouTube, Reddit, ChatGPT und Hacker News greift Defuddle auf eingebaute seitenspezifische Algorithmen zurück, die den relevanten Inhalt gezielt erkennen und aufbereiten. Genau dieser aufbereitete Inhalt landet dann in der {{content}}-Variable und damit in der Notiz. Der Lesemodus im Browser nutzt dieselben Algorithmen, weshalb er bei diesen Plattformen ebenfalls besonders gut funktioniert.
Die Standard-Vorlage ist damit ein guter Ausgangspunkt, den du durch Duplizieren und Anpassen für eigene Zwecke weiterentwickeln kannst.
Lesezeichen mit einer Auswahl
Das nächste Lesezeichen nutzt die gleiche Darstellung wie das Lesezeichen mit Preview. Es wird aber statt der Variable {{description}} die Variable {{selection}} verwendet, die eine zuvor auf der Webseite getroffene Auswahl enthält. Die Notiz nutzt das gleiche CSS-Snippet wie das Lesezeichen mit Preview.
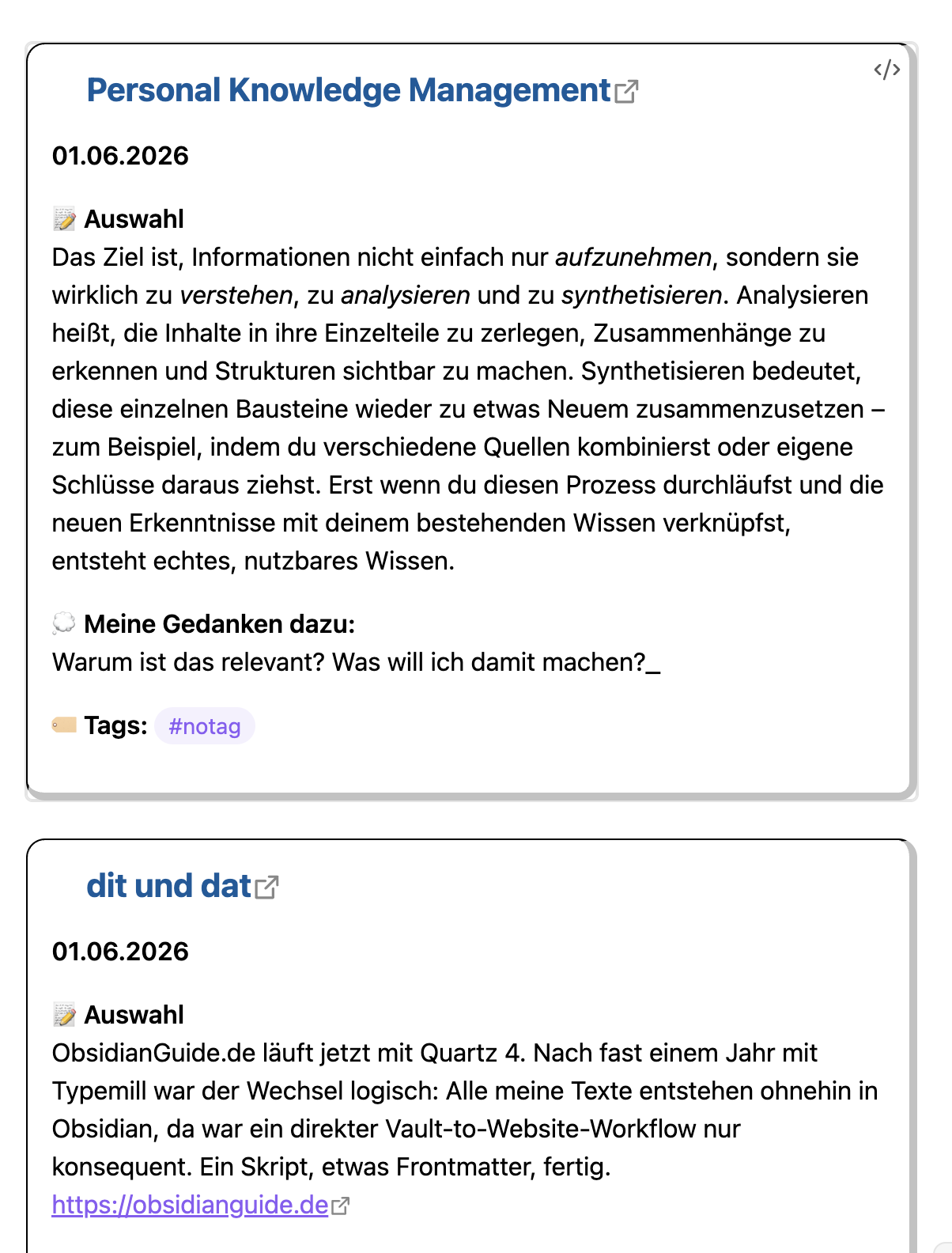
Der Notizinhalt sieht für diese Vorlage so aus:
> [!bookmark] **[{{title|safe_name}}]({{url}})**
>
> **{{date|date:"DD.MM.YYYY"}}**
>
> 📝 **Auswahl**
{{selection|blockquote}}
>
> 💭 **Meine Gedanken dazu:**
> _Warum ist das relevant? Was will ich damit machen?_
>
> 🏷️ **Tags:** #notagDie ersten zwei Zeilen erstellen den Callout-Typ und den Link zur Webseite und das Datum. Es folgt eine Bereichsüberschrift und dann die Auswahl als Variablen-Aufruf:
{{selection|blockquote}}
Hier gibt es eine Besonderheit im Vergleich zum Lesezeichen mit Preview. Dort steht die Variable direkt in einer Callout-Zeile: > {{description}}. Bei der {{selection}}-Variablen fehlt das führende >, weil der Filter blockquote diese Aufgabe übernimmt. Er stellt vor jeder Zeile der Auswahl beim Erstellen des Markdowns automatisch ein > voran. Das ist besonders wichtig, wenn die Auswahl aus mehreren Zeilen oder einer Aufzählungsliste besteht, da ein einzelnes > nur die erste Zeile abdecken würde.
Falls du auch bei der {{description}}-Variable auf mehrzeilige Inhalte stößt, kannst du dort denselben Filter verwenden: {{description|blockquote}}.
Nun folgt ein Bereich, der dazu einladen soll, schon bei der Erstellung eine kurze Notiz zu der geclippten Auswahl festzuhalten:
> 💭 **Meine Gedanken dazu:**
> _Warum ist das relevant? Was will ich damit machen?_Das gleiche gilt für die letzte Zeile:
> 🏷️ **Tags:** #notagDer Tag #notag hilft dabei, noch nicht verschlagwortete Clips schnell zu finden. Du kannst die Tags aber auch direkt beim Clippen eintragen, wenn du ohnehin schon einen Gedanken zur Auswahl festhältst.
Hier die Vorlage als JSON-Datei zum direkten Importieren:
{
"schemaVersion": "0.1.0",
"name": "Auswahl clippen",
"behavior": "prepend-specific",
"noteContentFormat": "> [!bookmark] **[{{title|safe_name}}]({{url}})**\n> **{{date|date:\"DD.MM.YYYY\"}}**\n>\n> 📝 **Auswahl**\n{{selection|blockquote}}\n>\n> 💭 **Meine Gedanken dazu:**\n> _Warum ist das relevant? Was will ich damit machen?_\n>\n> 🏷️ **Tags:** #notag",
"properties": [],
"triggers": [],
"noteNameFormat": "Bookmark mit Auswahl",
"path": "Bookmarks"
}Zusammenfassung
Dieses Beispiel zeigt, wie sich der Web Clipper gezielt für die Triage-Phase im Salustri-Modell einsetzen lässt. Statt den gesamten Seiteninhalt zu übernehmen, wird nur der relevante Ausschnitt geclippt. Der Filter blockquote löst dabei ein technisches Problem, das bei mehrzeiligen Inhalten ohne ihn auftreten würde. Der eingebaute Bereich für eigene Gedanken und Tags macht die Vorlage zu mehr als einem reinen Ablagesystem: Er fordert schon im Moment des Clippens zu einer ersten Auseinandersetzung mit dem Inhalt auf.
Arbeiten mit Markierungen
Der Obsidian Web Clipper kann beim Arbeiten mit Webseiten auch direkt helfen, da er eine Funktion bietet, mit der du auf beliebigen Seiten eigene und persistente Markierungen während des Lesens erstellen kannst. Diesen Modus erreichst du, indem du das Obsidian Web Clipper Menü öffnest und das Stift-Icon klickst.
Nun kannst du eine oder mehrere Textstellen markieren:
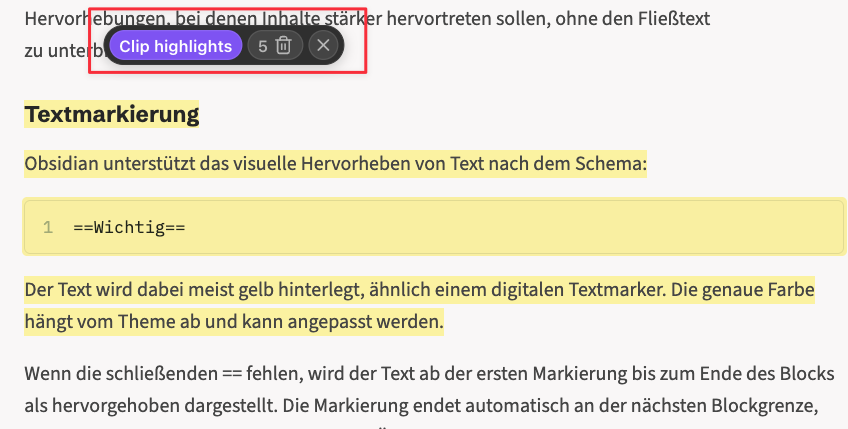
Der kleine schwarz hinterlegte Bereich zeigt dir an, dass du dich nun im Markierungs-Modus befindest. Er bietet außerdem Funktionen, mit dem du dann das Clippen der Webseite starten kannst oder alle Markierungen auf der Seite zu loschen. Mit einem Klick auf das xverläßt du den Modus. Aber solange du in diesem Modus befindest, wird jede Auswahl auf der Seite zu einer Markierung. Falls du eine Markierung löschen möchtest, klicke auf diese und dann auf den kleinen schwarzen Button „Remove”:

Diese Markierungen bleiben auf der Webseite bestehen, bis du sie löschst. Das gilt allerdings nur lokal für den aktuell benutzen Browser. Die Markierungen werden nicht über mehrere Browser hinweg synchronisiert.
Du kannst die Markierungen auch in den Einstellungen des Web Clippers verwalten, indem du den Button „Hervorhebungen öffnen” klickst:
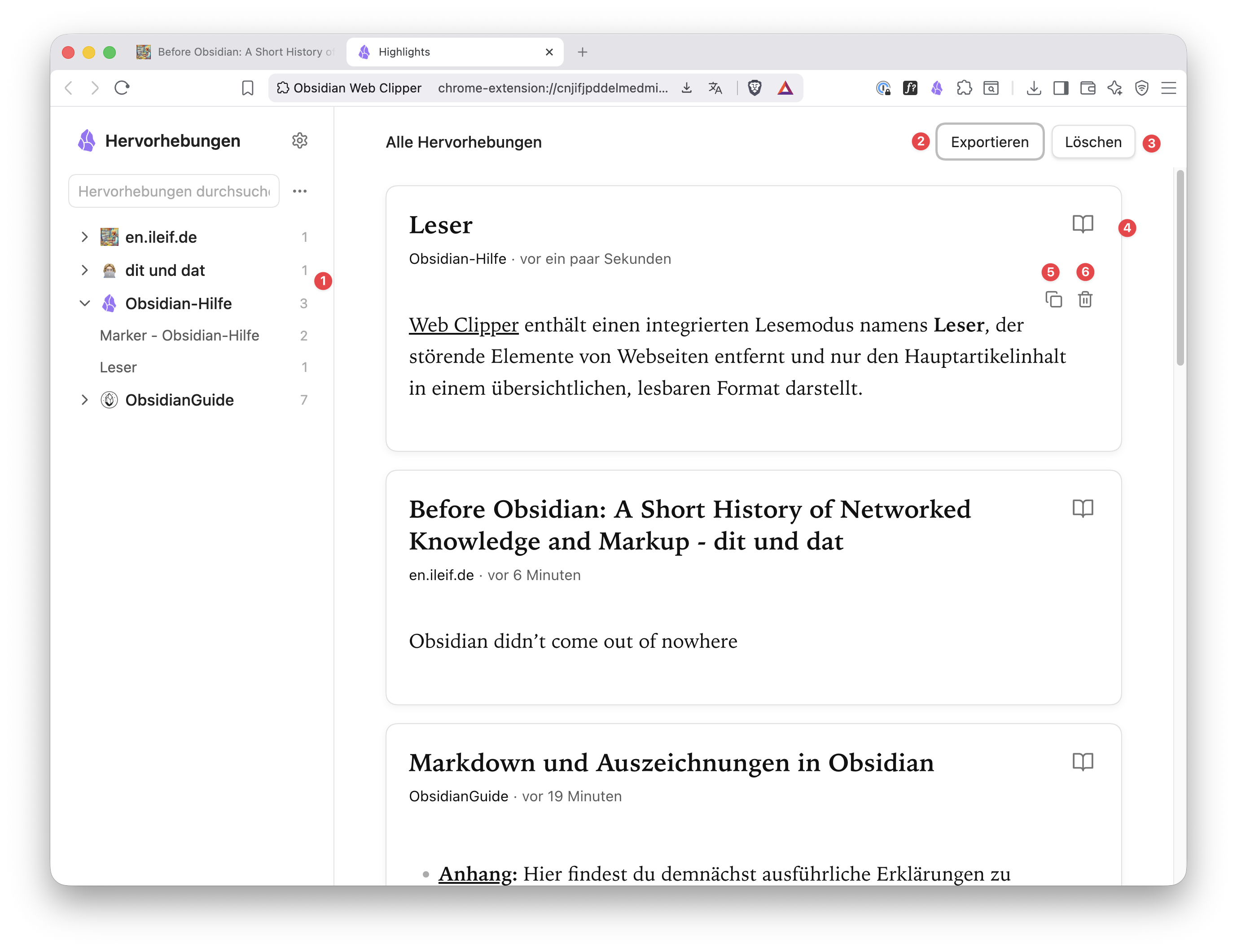
- (1) Zeigt die Liste der Webseiten, auf denen du Markierungen erstellt hast.
- (2) Mit dem Button „Exportieren” kannst du alle Markierungen als JSON-Datei speichern, falls du diese Daten weiterverarbeiten möchtest.
- (3) Mit dem Button „Löschen” werden alle Markierungen gelöscht.
- (4) Ein Klick auf das Buch-Icon öffnet die Webseite im Lesemodus.
- (5) Mit diesem Icon wird die Quelle mit der Markierung als Markdown gespeichert. Hier scheint Defuddle gelegentlich Probleme zu haben: Manchmal wird der Seitenname mit der vollständigen URL und dem markierten Text übernommen, im Falle dieses Guides wird aber nur der Pfad ohne Domain geclippt und oft auch nur der Text, obwohl im unter (2) gespeicherten JSON alle Daten vorhanden sind.
- (6) Mit dem Papierkorb wird diese Markierung gelöscht.
Markierungen clippen
Der einfachste Weg, Webseiten mit Markierungen in Notizen zu überführen, ist die Verwendung der Standard-Vorlage. Wenn du damit eine Webseite clippst, wird die gesamte Seite gespeichert und die Markierungen werden in der Obsidian-Notiz übernommen und mit der Auszeichnung für Markierungen versehen. Falls das bei dir nicht der Fall sein sollte kontrolliere ob du in den Einstellungen die Option „Seiteninhalt markieren” gewählt hast.
Alternativ kannst du auch nur die Markierungen clippen, wenn die Option „Seiteninhalt ersetzen” gewählt ist. Bei der Option „Nichts tun” wird nur der normale Hauptinhalt in der Variable {{content}} abgelegt. Das gilt nicht nur für die Standard-Vorlage, sondern für alle Vorlagen in denen du die Variable {{content}} verwendest.
Markierungen mit der Variable {{highlights}}
Eine weitere Möglichkeit, Markierungen mit einer Vorlage zu clippen, bietet die Variable {{highlights}}. Ohne die Verwendung von Filter enthält sie ein JSON-Array, also eine Liste von Objekten, mit den zwei Feldern text und timestamp:
[
{"text": "Willkommen in der dunklen Ecke von Obsidian",
"timestamp": "2026-06-01T21:05:16.453Z"},
{"text": "kein Bugtracker, sondern eine Mischung aus technischem Tagebuch und Erfahrungsarchiv",
"timestamp": "2026-06-01T21:05:16.453Z"}
]Mit einem oder mehreren Filtern lässt sich steuern, was aus diesem Array in die Notiz geschrieben wird.
Einfache Liste
Der folgende Ausdruck extrahiert aus jedem Objekt im Array das Feld text und wandelt die resultierende Liste mit dem Filter list in eine Markdown-Aufzählungsliste um:
{{highlights|map: item => item.text|list}}
Ergebnis:
- Willkommen in der dunklen Ecke von Obsidian
- kein Bugtracker, sondern eine Mischung aus technischem Tagebuch und ErfahrungsarchivNummerierte Liste als Callout
Der nächste Beispiel erweitert das Prinzip. Der Filter list:numbered erzeugt statt einer Aufzählungsliste eine nummerierte Liste. Der Filter callout verpackt das Ergebnis anschließend in einen Callout vom Typ quote mit dem Titel „Highlights”:
{{highlights|map: item => item.text|list:numbered|callout:("quote", "Highlights")}}
Als Markdown:
> [!quote] Highlights
>
> 1. Willkommen in der dunklen Ecke von Obsidian
> 2. kein Bugtracker, sondern eine Mischung aus technischem Tagebuch und ErfahrungsarchivWas in Obsidian so aussieht:
Highlights
- Willkommen in der dunklen Ecke von Obsidian
- kein Bugtracker, sondern eine Mischung aus technischem Tagebuch und Erfahrungsarchiv
Liste mit Fragment-Links
In dem letzten Beispiel wird ebenfalls eine Liste erzeugt, aber jeden Eintrag wird um einen Fragment-Link ergänzt, der bei einem Klick direkt zur markierten Stelle auf der Originalwebseite springt und dort die entsprechende Textstelle mit einer Markierungsfarbe anzeigt. Dafür sorgt der Filter fragment_link, der das Array intern um diesen Fragment-URL erweitert. Der anschließende map-Filter extrahiert daraus das fertig formatierte text-Feld mit dem Markdown-Link:
{{highlights|fragment_link|map: item => item.text|list}}
Als Markdown:
- Willkommen in der dunklen Ecke von Obsidian [link](https://obsidianguide.de/04-anhang/Feinheiten-und-Fallstricke/#:~:text=Willkommen%20in%20der%20dunklen%20Ecke%20von%20Obsidian)
- kein Bugtracker, sondern eine Mischung aus technischem Tagebuch und Erfahrungsarchiv [link](https://obsidianguide.de/04-anhang/Feinheiten-und-Fallstricke/#:~:text=kein%20Bugtracker%2C%20sondern%20eine%20Mischung%20aus%20technischem%20Tagebuch%20und%20Erfahrungsarchiv)So würde es in der Notiz erscheinen (die blaue Box dient hier nur zur Abgrenzung vom normalen Text):
Box
Die farbliche Hinterlegung in der Originalwebseite ist übrigens kein Feature von dem Obsidian Web Clipper, sondern wird von den Browser erzeugt. Du kannst so einen Link auch an jemanden weiterleiten, der keinen Web Clipper installiert hat.
Zusammenfassung
Markierungen sind ein eigenständiges Feature des Web Clippers, das unabhängig vom Clippen funktioniert und direkt beim Lesen einer Webseite eingesetzt werden kann. Sie bleiben persistent im Obsidian Web Clipper gespeichert und lassen sich über die Einstellungen verwalten und exportieren.
Beim Clippen bietet die Variable {{highlights}} den direkten Zugriff auf alle Markierungen einer Seite. Kombiniert mit Filtern wie map, list, callout und fragment_link lässt sich das Ergebnis sehr flexibel gestalten, von einer einfachen Aufzählungsliste bis hin zu einer nummerierten Liste im Callout mit direkten Links zurück zur Originalquelle. Die Filterkette zeigt dabei exemplarisch wie sich im Web Clipper mehrere Filter zu komplexen Transformationen kombinieren lassen.
Schema, Meta und Selector-Variablen
Bisher hast du nur Variablen verwendet, die Defuddle beim Verarbeiten einer Webseite automatisch befüllt, also {{title}}, {{url}} oder {{description}}. Der Web Clipper bietet aber noch drei weitere Variablentypen, die einen direkten Zugriff auf strukturierte Daten einer Webseite ermöglichen: Schema-Variablen, Meta-Variablen und Selector-Variablen.
Bevor du eine Vorlage mit diesen Variablen baust, lohnt sich ein Blick auf das eingebaute Werkzeug des Web Clippers, das dir zeigt welche Daten auf einer Seite überhaupt verfügbar sind.
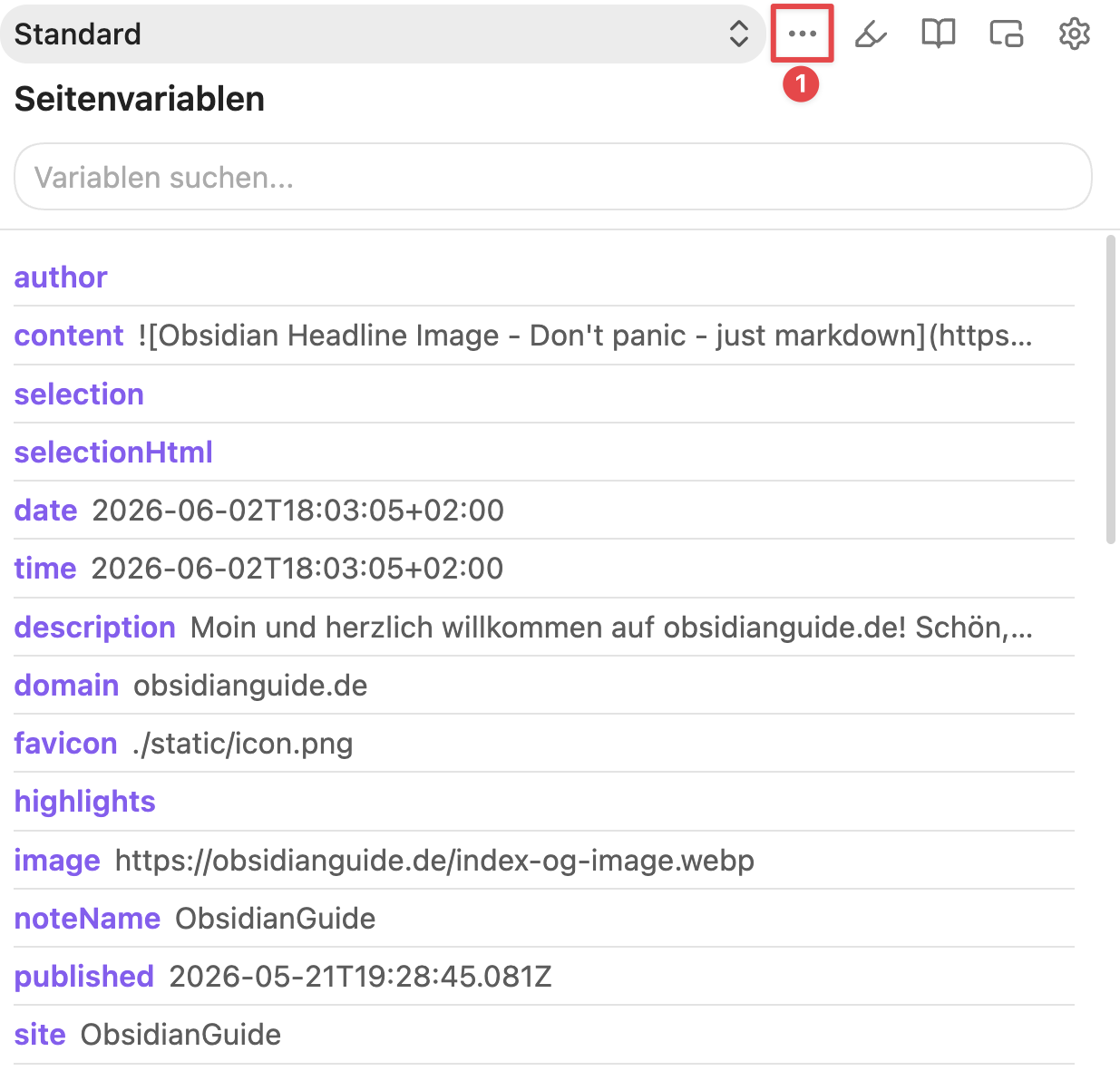
Wenn du auf einer Webseite den Web Clipper öffnest und unten auf „Seitenvariablen” (1) klickst, siehst du eine Übersicht aller Variablen und deren potenziellen Inhalte, die der Web Clipper auf der Seite gefunden hat, inklusive der Schema- und Meta-Daten. Das ist der schnellste Weg herauszufinden, welche Felder du in einer Vorlage verwenden kannst.
Schema-Variablen am Beispiel IMDb
Schema-Variablen ermöglichen den Zugriff auf strukturierte Metadaten, die Webseitenbetreiber nach dem Schema.org-Standard maschinenlesbar im Hintergrund hinterlegen, die aber für den normalen Besucher unsichtbar sind. Sie beschreiben ähnlich wie die Notiz-Eigenschaften in Obsidian den Inhalt der Webseite. Die Initiative dazu ging seinerzeit von den großen Suchmaschinenanbietern aus, um Webseiten besser in den jeweiligen Suchindex aufnehmen zu können. Der Standard ist auf schema.org publiziert.
Als Beispiel für eine Vorlage, die auf Schema-Variablen basiert, bietet sich die Filmdatenbank IMDb an, da jede Filmseite ein umfangreiches Schema.org-Datenset mitliefert. Verfügbar sind unter anderem name für den Filmtitel, description für die Kurzbeschreibung, image für das Filmplakat, datePublished für das Erscheinungsdatum sowie director und author für Regie und Drehbuch. Wenn du eine Übersicht über die verfügbaren Schema-Variablen haben möchtest, lass dir wie oben beschrieben die Seitenvariablen anzeigen.
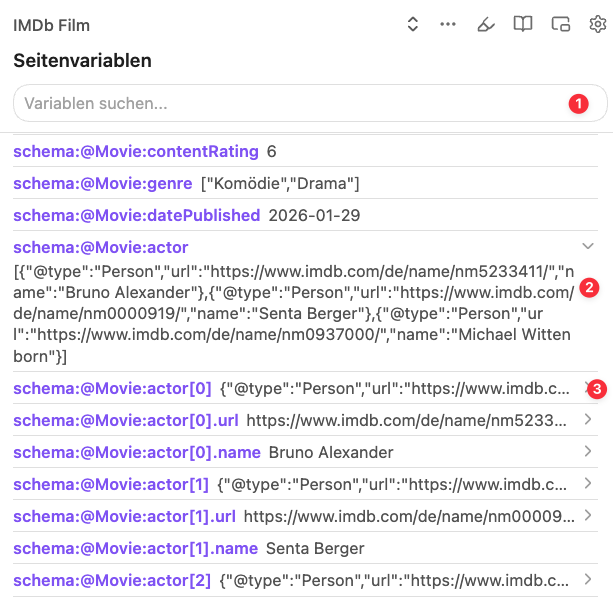
Du kannst durch die Liste der Variablen in dem Popup blättern oder direkt nach einem Ausdruck suchen (1). Als Beispiel zeigt das Bild die Variable actor (2), die für die Vorlage relevant sein wird. Die Variable actor beinhaltet ein Array mit den Schauspielern als Objekte mit ihren jeweiligen Eigenschaften. Darunter (3) werden alle Objekte des Arrays mit ihren Indizes angezeigt, für die Vorlage ist aber nur (2) relevant.
Mit dem Ausdruck {{schema:actor|map: d => d.name|wikilink|list}} lässt sich eine Liste der Schauspieler als Wikilinks erstellen. Der map-Filter erzeugt ein neues Array das nur noch die Namen enthält, wikilink wandelt jeden Namen in einen Wikilink um, und list gibt das Array als Markdown-Aufzählungsliste aus.
Eigentlich wäre es schön gewesen, statt eines Wikilinks die Eigenschaft url zu verwenden, die auf die jeweilige IMDb-Seite des Schauspielers zeigt. Dem Web Clipper fehlt aber eine Funktion um Strings zusammenzubauen, also [Name](URL) aus zwei getrennten Feldern zu erzeugen. Für die Notizeigenschaften bleibt daher nur der Wikilink-Ansatz, oder eine einfache Textliste ohne Verlinkung.
Im Notizinhalt ist das jedoch möglich, weil dort Schleifen verwendet werden und die Variablen dann in normalen Markdown verwendet werden können:
{% for actor in schema:actor %}
- [{{actor.name}}]({{actor.url}})
{% endfor %}
Die Schleife geht Item für Item durch das Array und baut für jeden Schauspieler einen Markdown-Link mit Name und IMDb-URL zusammen.
Die IMDb-Vorlage
Hier zunächst die Vorlage zum Einfügen in den Obsidian Web Clipper. Kopiere das folgende JSON, drücke in den Vorlagen-Einstellungen den „Importieren”-Button und füge das JSON ein.
{
"schemaVersion": "0.1.0",
"name": "IMDb",
"behavior": "create",
"noteContentFormat": "\n\n{{schema:description}}\n\n## Credits\n\n**Regie**\n{% for director in schema:director %}\n- [{{director.name}}]({{director.url}})\n{% endfor %}\n\n**Drehbuch**\n{% for author in schema:author %}\n- [{{author.name}}]({{author.url}})\n{% endfor %}\n\n**Stars**\n{% for actor in schema:actor %}\n- [{{actor.name}}]({{actor.url}})\n{% endfor %}\n\n## Details\n| | |\n|---|---|\n| **Genre:** | {{schema:genre|join:\", \"}} |\n| **Laufzeit:** | {{schema:duration|duration}} |\n| **Bewertung:** | {{schema:aggregateRating.ratingValue}} / 10 ({{schema:aggregateRating.ratingCount}} Stimmen) |\n\n## Meine Notiz\n\n_Was hat mich an diesem Film interessiert?_",
"properties": [
{
"name": "title",
"value": "{{schema:name}}",
"type": "text"
},
{
"name": "alternate_title",
"value": "{{schema:alternateName}}",
"type": "text"
},
{
"name": "erschienen",
"value": "{{schema:datePublished|date:\"YYYY-MM-DD\"}}",
"type": "date"
},
{
"name": "regie",
"value": "{{schema:director|map: d => d.name|wikilink|join:\", \"}}",
"type": "multitext"
},
{
"name": "genre",
"value": "{{schema:genre|join:\", \"}}",
"type": "multitext"
},
{
"name": "bewertung",
"value": "{{schema:aggregateRating.ratingValue}}",
"type": "number"
},
{
"name": "quelle",
"value": "{{url}}",
"type": "text"
},
{
"name": "erstellt",
"value": "{{date|date:\"YYYY-MM-DD\"}}",
"type": "date"
},
{
"name": "cssclasses",
"value": "imdb-note",
"type": "multitext"
}
],
"triggers": [
"https://www.imdb.com"
],
"noteNameFormat": "{% set filmtitel = schema:alternateName ?? schema:name %}{{filmtitel|safe_name}}",
"path": "Filme"
}Du solltest nun eine neue Vorlage mit dem Namen „IMDb” sehen. Da das JSON etwas unübersichtlich ist, schauen wir uns die relevanten Felder in der Ansicht „Vorlage bearbeiten” an.
Vorlagenname
Hier sollte nun „IMDb” stehen. Falls nicht, versuche die Vorlage nochmals zu importieren.
Vorlagen-Trigger
Mit dem Trigger wird sichergestellt, dass die Vorlage auf einer Seite von IMDB als Standard angeboten wird. Eingetragen ist hier die URL https://www.imdb.com. Auch wenn du nur https://imdb.com eingibst, leitet der Browser automatisch auf https://www.imdb.com weiter. So wird das hier funktionieren, aber nicht alle Webseiten verhalten sich so. Daher bietet Web Clipper auch die Möglichkeit komplexere Muster mit regulären Ausdrücken zu definieren. Im folgenden RegEx macht das https? das s optional, (www\.)? macht das www. optional. Subdomains wie mail.example.com passen nicht, weil nach https?:// nur optional www. erlaubt ist und nichts anderes. Also bei http://example.comund http://www.example.com aber nicht bei https://mail.example.com wird diese Vorlage zum Standard.
/^https?:\/\/(www\.)?example\.com/Leider unterscheidet IMDb nicht in der URL zwischen Filmseiten und anderen Seiten, obwohl für Serien oder Personen andere Schema-Sets verwendet werden. Aber auf anderen Webseiten können so nur bestimmte Pfade mit einer RegEx-Definition eingeschlossen werden auf denen eine Vorlage zum Standard wird.
Tipp
Der Web Clipper erkennt z.B. auch
"schema:@Recipe"als Trigger und aktiviert die Vorlage automatisch wenn er einen solchen Webseite mit@type: Recipefindet. Das Schöne daran ist dass du dann auch die Schema.org Felder direkt als Variablen nutzen wie kannst:
{{schema:Recipe:name}}
{{schema:Recipe:recipeIngredient}}
{{schema:Recipe:recipeInstructions}}
{{schema:Recipe:totalTime}}
Das macht Rezeptvorlagen extrem zuverlässig weil die Daten strukturiert und sauber sind, unabhängig davon wie die Seite optisch aufgebaut ist. Andere nützliche Types sind `schema:@Article`, `schema:@Product`, `schema:@Event` oder `schema:@Person`. Welche Schema Felder sich im Standard hinter einem solchen Typ befinden sollten kannst du auf der Webseite [schema.org](https://schema.org) finden. Hier der direkte Link zu den Felder des Typs [Rezepte](https://schema.org/Recipe)
Speicherort
Hier kannst du den Ordner in deinem Vault festlegen, in dem diese Notizen gespeichert werden. In der Vorlage ist Filme angegeben. Falls der Ordner noch nicht existiert, wird er beim Anlegen der ersten Notiz automatisch erstellt.
Notizname
IMDb bietet oft zwei Namen an: den Originaltitel wie „Monty Python and the Holy Grail” als schema:name und den deutschen Titel „Die Ritter der Kokosnuß” als schema:alternateName. Bei deutschsprachigen Filmen ist der Titel direkt in schema:name hinterlegt und schema:alternateName ist oft nicht vorhanden.
Damit als Notiztitel der deutsche Name verwendet wird, kannst du {{schema:alternateName ?? schema:name}} eintragen. Der ??-Operator, der Nullish Coalescing Operator, bedeutet: verwende schema:alternateName, falls vorhanden, sonst schema:name als Fallback.
Da aber nicht sichergestellt ist, dass diese Variablen keine Zeichen enthalten, die als Dateiname nicht erlaubt sind, sollte noch der Filter safe_name angewendet werden. Allerdings kann der Filter nicht auf die beiden Namen einzeln angewendet und gleichzeitig mit ?? kombiniert werden. Der Trick ist, den Namen wie oben beschrieben zu ermitteln und in eine temporäre Variable zu schreiben, auf die der Filter dann angewendet wird:
{% set filmtitel = schema:alternateName ?? schema:name %}{{filmtitel|safe_name}}
Eigenschaften
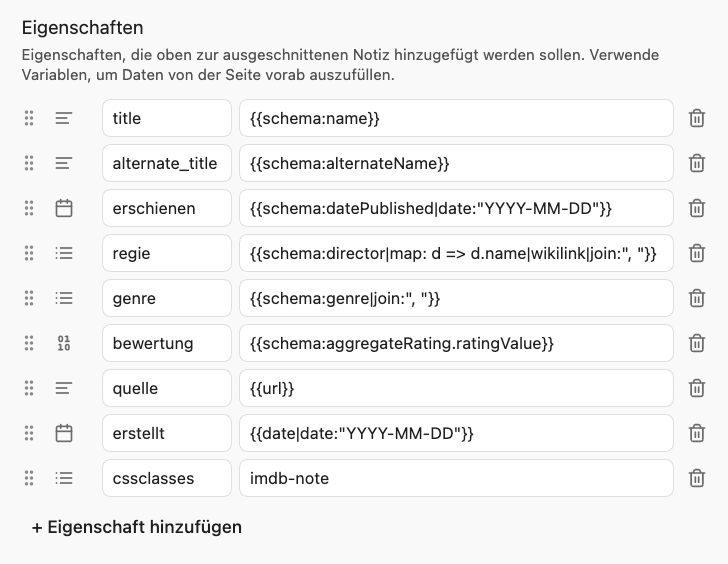
In den Eigenschaften sind beide Namen des Films als title und alternate_title aufgenommen. Da es einen oder mehrere Regisseure geben kann, hat die Eigenschaft regie den Typ Liste und die Regisseure werden als Wikilinks ausgegeben. Wenn du keine eigenen Seiten für Regisseure anlegen möchtest, kannst du wikilink| einfach aus dem Ausdruck entfernen.
Die Eigenschaft genreist eine einfache Liste, in der die einzelnen Genres als Item abgelegt werden.
Für die Eigenschaft bewertung wird der Wert aus aggregateRating.ratingValue als Zahl ausgelesen. Falls du weitere Bewertungsfelder benötigst, kannst du diese in den Seitenvariablen nachschlagen.
Im Notizinhalt wird eine Tabelle nur als Layout-Element verwendet, damit Feldnamen und Werte sauber aneinander ausgerichtet sind. Die Tabellenrahmen sollen dabei nicht sichtbar sein. Die Eigenschaft cssclasses mit dem Wert imdb-note sorgt dafür, dass ein CSS-Snippet nur in Notizen mit dieser Eigenschaft aktiv wird und die Rahmen ausblendet.
.imdb-note table { border: none; }
.imdb-note td, .imdb-note th { border: none; padding: 0.15rem 1rem 0.15rem 0; min-width: unset; }
.imdb-note tr { border: none; background: none; }Wie CSS-Snippets angelegt und aktiviert werden ist unter Lesezeichen mit Preview erklärt. Je nach Vault-Organisation könntest du noch weitere Eigenschaften ergänzen, etwa type für die Unterscheidung von Notiztypen oder tags für die Verschlagwortung.
Notizinhalt
Der Notizinhalt ist bewusst einfach gehalten:

{{schema:description}}
## Credits
**Regie**
{% for director in schema:director %}
- [{{director.name}}]({{director.url}})
{% endfor %}
**Drehbuch**
{% for author in schema:author %}
- [{{author.name}}]({{author.url}})
{% endfor %}
**Stars**
{% for actor in schema:actor %}
- [{{actor.name}}]({{actor.url}})
{% endfor %}
## Details
| | |
|---|---|
| **Genre:** | {{schema:genre|join:", "}} |
| **Laufzeit:** | {{schema:duration|duration}} |
| **Bewertung:** | {{schema:aggregateRating.ratingValue}} / 10 ({{schema:aggregateRating.ratingCount}} Stimmen) |
## Meine Notiz
_Was hat mich an diesem Film interessiert?_Mit  wird das Filmplakat angezeigt, dessen URL in schema:image hinterlegt ist. Für Regie, Drehbuch und Besetzung wird die oben erklärte Schleife verwendet, um eine Liste mit Links zu erzeugen, die auf die IMDb-Seite der jeweiligen Person zeigen.
Für den Details-Abschnitt wurden exemplarisch einige Felder herausgegriffen. Die Laufzeit ist im ISO 8601-Format für eine Zeitdauer abgelegt, für einen Film mit 91 Minuten also PT1H31M. Der Filter duration wandelt das in die lesbare Schreibweise 01:31:00 um. Die Bewertung im Notizinhalt ist im Vergleich zur Eigenschaft bewertung etwas ausführlicher gestaltet, neben dem Wert selbst wird auch das Maximum /10 und die Anzahl der abgegebenen Bewertungen angezeigt.
Die Details werden als Tabelle dargestellt, damit Feldnamen und Werte sauber aneinander ausgerichtet sind. Ohne das imdb-note-CSS-Snippet sieht die Tabelle so aus:
| Genre: | Abenteuer, Komödie, Fantasy |
| Laufzeit: | 01:31:00 |
| Bewertung: | 8.1 / 10 (603624 Stimmen) |
Mit aktiviertem Snippet werden die Rahmen und die leeren Spaltenüberschriften ausgeblendet, sodass die Tabelle nur noch als Layout-Element dient.
Am Ende der Vorlage folgt noch ein freier Bereich für deine eigene Notizen.
Schema-Variablen im Überblick
Schema-Variablen erschließen eine Informationsebene, die auf vielen Webseiten vorhanden aber für den normalen Besucher unsichtbar ist. Wenn du wissen möchte was auf einer Seite verfügbar ist, nutze am besten die Seitenvariablen-Ansicht des Web Clippers bevor du eine spezielle Vorlage baust.
Das IMDb-Beispiel zeigt wie weit Schema-Variablen reichen können: Titel, Beschreibung, Plakat, Erscheinungsdatum, Regie, Drehbuch, Besetzung, Genre, Laufzeit und Bewertung lassen sich alle ohne einen einzigen Selektor aus den strukturierten Daten der Seite auslesen. Neu hinzugekommen sind dabei zwei Konzepte: der ??-Operator für Fallback-Werte wenn eine Variable nicht vorhanden ist, und die {% for %}-Schleife die es erstmals ermöglicht, Arrays vollständig mit formatiertem Inhalt auszugeben, also zum Beispiel jeden Schauspieler als klickbaren Link zur IMDb-Seite.
Selektoren-Variablen
Neben den vordefinierten Variablen wie {{title}} oder {{url}} und den Schema-Variablen bietet der Web Clipper noch eine weitere Möglichkeit, gezielt Inhalte aus einer Webseite zu extrahieren. Mit Selektoren lassen sich einzelne HTML-Elemente direkt ansprechen und deren Inhalt als Variable verwenden.
In diesem Abschnitt möchte ich auf diese Möglichkeit der Selektoren-Variablen eingehen. Allerdings hatte ich das Problem, dass es bei den meisten Webseiten kaum Sinn macht den Weg mit den Selektoren zu gehen, da der Obsidian Web Clipper mit den anderen Möglichkeiten der Variablen Bildung viel einfacher zu konfigurieren ist und die Ergebnisse oft besser aussehen. Aus diesem Grund habe ich eine kleine Demo-Seite gebaut, die mit eindeutigen CSS-Klassen ausgestattet ist und das Prinzip der Selektoren gut veranschaulicht. Die passende Vorlage steht ebenfalls als zip-Datei zum Download bereit.
Der Web Clipper liest den HTML-Quelltext so wie er vom Server geliefert wird. Die Demo-Seite liegt daher nicht nur lokal, sondern auf einem Webserver, damit alle Pfade korrekt aufgelöst werden können.
Zwei Arten von Selektoren
{{selector:h1.article-title}}
{{selector:...}} gibt den reinen Textinhalt eines Elements zurück, ohne jegliche HTML-Formatierung. Gut geeignet für Frontmatter-Felder wie Autor, Kategorie oder Lesezeit.
{{selectorHtml:article.main-content .prose|markdown|trim}}
{{selectorHtml:...}} gibt den HTML-Inhalt zurück. Er wird fast immer zusammen mit Filtern verwendet, zum Beispiel um HTML in Markdown umzuwandeln oder Leerzeichen zu entfernen.
Textinhalte per Selektor
Im HTML der Demo-Seite sind die relevanten Elemente mit sprechenden Klassen versehen, was eigentlich in einem strukturierten HTML immer der Fall sein sollte, aber leider nicht ist:
<div class="article-category">Wissensmanagement</div>
<h1 class="article-title">Die Kunst des Notierens</h1>
<p class="article-lead">Warum handgeschriebene Notizen das Denken
schärfen und wie du ein System aufbaust, das wirklich funktioniert.</p>
<div class="author-name">ObsidianGuide Redaktion</div>
<span class="reading-time">6 Minuten</span>Die passenden Selektoren in der Vorlage greifen diese Elemente direkt ab:
{{selector:.article-category}} → Wissensmanagement
{{selector:h1.article-title}} → Die Kunst des Notierens
{{selector:.article-lead}} → Warum handgeschriebene Notizen...
{{selector:.author-name}} → ObsidianGuide Redaktion
{{selector:.reading-time}} → 6 Minuten
Datum aus dem Meta-Tag
Auch das Veröffentlichungsdatum steht nicht im sichtbaren Text, sondern als Open Graph Meta-Tag im <head>-Abschnitt der Seite:
<meta property="article:published_time" content="2026-06-04">Dafür gibt es die {{meta:...}} Variable, die direkt auf Meta-Tags zugreift:
{{meta:article:published_time|date:"YYYY-MM-DD"}} → 2026-06-04
Ein Bild per Selektor
Wenn ein Bild in einem eindeutigen Container-Element liegt, lässt es sich zuverlässig ansprechen. Das Hero-Bild der Demo-Seite hat genau das:
<div class="hero-image">
<img src="https://demo.obsidianguide.de/notebook.png">
</div>{{selectorHtml:.hero-image img|markdown|trim}}
→ 
Damit die Bildpfade korrekt aufgelöst werden, müssen die Bilder mit absoluten URLs im HTML eingetragen sein. Ein relativer Pfad wie notebook.png funktioniert im Browser, der Web Clipper kann ihn aber nicht selbständig zu einer vollständigen URL ergänzen. Zumindest habe ich keinen Weg gefunden.
Sobald mehrere Elemente mit der gleichen Klasse auf der Seite vorhanden sind, liefert der Selektor alle Treffer als JSON-Array zurück, was in meinen Tests zu einem kaputten Ergebnis führte. In diesem Fall ist es einfacher, die Bilder über den Artikeltext-Selektor mitzunehmen, da sie dort ebenfalls enthalten sind, wie es mit dem zweiten Bild auf der Seite geschieht.
Artikeltext per Selektor
Der gesamte Fließtext mit Überschriften, Hervorhebungen und eingebetteten Bildern liegt im .prose-Bereich des Artikels:
<article class="main-content">
<div class="prose">
<p>Es gibt einen Moment, den viele kennen...</p>
<h2>Schreiben als Denken</h2>
<p>Handschriftliche Notizen haben einen...</p>
</div>
</article>Der Selektor kombiniert beide Ebenen, um nur den Artikelbereich zu treffen und nicht die Sidebar:
{{selectorHtml:article.main-content .prose|markdown|trim}}
→ Es gibt einen Moment, den viele kennen...
## Schreiben als Denken
Handschriftliche Notizen haben einen...
Die im Fließtext eingebetteten Bilder werden dabei automatisch als Markdown-Bildlinks mit ausgegeben.
Warum Selektoren überhaupt nötig sind
Moderne Webseiten sind selten so aufgebaut, dass der Hauptinhalt alleine auf der Seite steht. Navigation, Sidebar, Footer, Cookie-Banner, verwandte Artikel,all das landet ohne gezielten Selektor zusammen mit dem eigentlichen Inhalt in der Notiz, wenn man einfach {{content}} verwendet. Ein Selektor wie article.main-content .prose grenzt den Bereich weiter ein und holt nur das heraus, was für dich wirklich relevant ist.
Das gilt auch für Markierungen. Wenn du vor dem Clippen Text auf der Seite markierst, stellt der Web Clipper diese Markierungen über die Variable {{highlights}} zur Verfügung. In der Beispiel-Vorlage lassen sie sich als Liste am Ende der Notiz ausgeben:
{{highlights}}
Das Ergebnis sind die markierten Textstellen als Aufzählungsliste, direkt verknüpft mit der Originalseite. So lässt sich gezieltes Lesen und Archivieren gut kombinieren, ohne den gesamten Artikeltext mitzunehmen.
Filter
Die Filter hast du ja schon kennengelernt. Im Beispiel wird das HTML in der Klasse prose zum einen in Markdown (|markdown) umgewandelt. Dadurch bleiben die Formatierungen, wie Links, Fettschrift, Überschriften und Bilder, des Inhalts erhalten. Der Filter |trim entfernt führende und nachfolgende Leerzeichen von dem Text.
{{selectorHtml:.prose|markdown|trim}}
Folgende Filter kennst du schon, aber der Vollständigkeit halber seien sie auch nochmals erwähnt:
|safe_name entfernt Sonderzeichen die in Dateinamen nicht erlaubt sind. Er wird vor allem für den Dateinamen der Notiz eingesetzt:
{{selector:h1.article-title|safe_name}}
→ Die Kunst des Notierens
|date:"YYYY-MM-DD" formatiert ein Datum in das gewünschte Format:
{{meta:article:published_time|date:"YYYY-MM-DD"}}
→ 2026-06-04
|list gibt mehrere Treffer als Liste aus statt als JSON-Array. Nützlich wenn ein Selektor mehrere gleichartige Textelemente trifft:
<span class="tag">PKM</span>
<span class="tag">Zettelkasten</span>
<span class="tag">Werkzeuge</span>{{selectorHtml:.tag|list}}
→ - PKM
- Zettelkasten
- Werkzeuge
Meta-Variablen
Meta-Variablen funktionieren nach dem gleichen Prinzip wie die Schema-Variablen, nur dass sie nicht auf strukturierte Schema-Daten zugreifen, sondern auf die <meta>-Tags im <head>-Abschnitt einer Seite. Diese Tags sind auf den meisten Webseiten vorhanden und werden in der Regel automatisch vom CMS oder Static Site Generator generiert.
Ein typischer <head>-Abschnitt sieht so aus:
<meta name="author" content="ObsidianGuide Redaktion">
<meta name="description" content="Warum handgeschriebene Notizen das Denken schärfen.">
<meta property="og:title" content="Die Kunst des Notierens">
<meta property="article:published_time" content="2026-06-04">
<meta property="article:author" content="ObsidianGuide Redaktion">
<meta property="article:tag" content="PKM">Der Zugriff erfolgt über {{meta:...}} mit dem jeweiligen Property-Namen:
{{meta:author}} → ObsidianGuide Redaktion
{{meta:description}} → Warum handgeschriebene Notizen...
{{meta:og:title}} → Die Kunst des Notierens
{{meta:article:published_time}} → 2026-06-04
{{meta:article:tag}} → PKM
Filter lassen sich wie gewohnt anhängen. Das Datum aus dem obigen Beispiel wird so in das gewünschte Format gebracht:
{{meta:article:published_time|date:"YYYY-MM-DD"}} → 2026-06-04
Im Unterschied zu Schema-Variablen gibt es bei Meta-Tags keinen verbindlichen Standard der vorschreibt, welche Felder eine Seite setzen muss und wie sie benannt sein sollen. Der og:-Namensraum folgt dem Open Graph Protocol, der article:-Namensraum ist eine Erweiterung davon, aber Tags wie name="author" oder name="keywords" sind schlicht informelle Konventionen. In der Praxis bedeutet das, dass du vor dem Einsatz einer Meta-Variable kurz im Quelltext der Zielseite nachschauen solltest, ob und wie das gewünschte Feld dort tatsächlich gesetzt ist.
Zusammenfassung
Schema-, Meta- und Selektor-Variablen erschließen drei unterschiedliche Informationsebenen einer Webseite. Schema-Variablen liefern die zuverlässigsten Ergebnisse, weil sie auf einem verbindlichen Standard basieren und die Daten sauber strukturiert vorliegen. Meta-Variablen sind weit verbreitet, folgen aber keinem einheitlichen Standard, weshalb es sich lohnt vor dem Einsatz einen Blick in den Quelltext der Zielseite zu werfen. Selektor-Variablen sind am flexibelsten, aber auch am stärksten von der Qualität der HTML-Struktur der Zielseite abhängig.
Für die meisten Anwendungsfälle reichen die vordefinierten Variablen kombiniert mit Schema- oder Meta-Variablen vollkommen aus. Die Seitenvariablen-Ansicht des Web Clippers zeigt dir schnell, was auf einer bestimmten Seite verfügbar ist, bevor du eine Vorlage baust.
Auswertung mit KI
Der Obsidian Web Clipper bietet die Möglichkeit, in Vorlagen ein Sprachmodell einzubinden und so zum Beispiel Zusammenfassungen von Webseiten zu erstellen oder wichtige Punkte in einem Text zu finden und aufzulisten.
Dazu kannst du entweder lokale Modelle, zum Beispiel mit Ollama, oder Modelle von externen Anbietern einbinden.
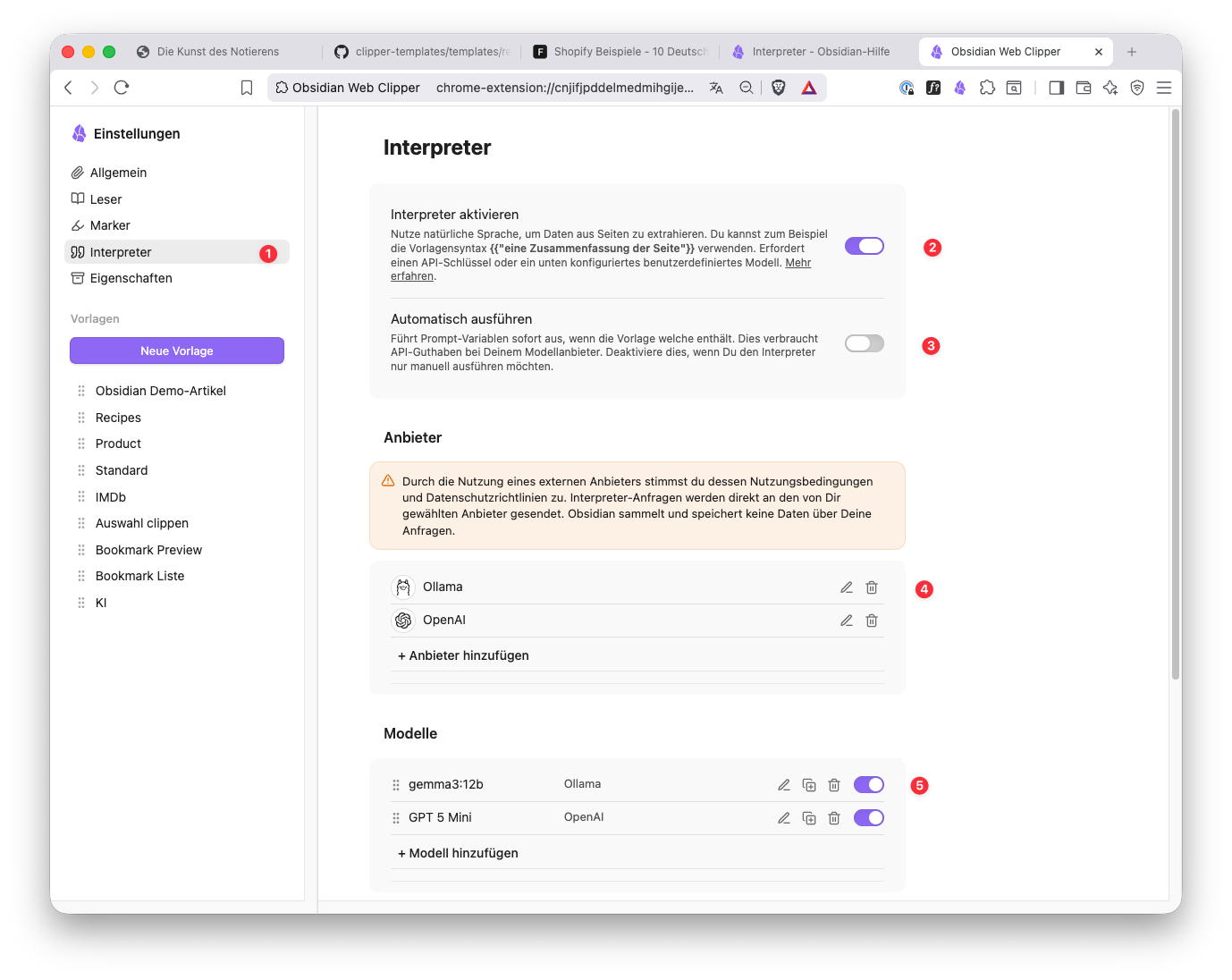
Die notwendigen Einstellungen kannst du in den Web Clipper Einstellungen (1) vornehmen.
Interpreter aktivieren (2): Mit dieser Option schaltest du das Feature an.
Automatisch ausführen (3): Wenn die Option aktiv ist, startet die Auswertung sofort, wenn du die Vorlage aufrufst. Leider bedeutet das nicht, dass du temporär auf die Auswertung verzichten kannst, denn wenn du den „Zu Obsidian hinzufügen” Button klickst, wird die Modell-Auswertung gestartet.
Anbieter (4): In diesem Abschnitt kannst du die Anbieter einstellen, die du nutzen möchtest. Du brauchst die Zugangsdaten für die jeweiligen APIs, die normalerweise nicht mit den regulären Zugangsdaten abgedeckt sind und zusätzliche Kosten verursachen können.
- Anbieter (A): Über die Dropdown-Liste kannst du deinen Anbieter auswählen.
- Basis-URL (B): Das ist die URL über die der Service aufgerufen wird. Sie wird bei der Auswahl des Anbieters automatisch ausgefüllt.
- API-Schlüssel: Mit dem API-Schlüssel identifizierst du dich gegenüber dem Service. Wie du einen API-Schlüssel erhältst, erfährst du über den Info-Link.
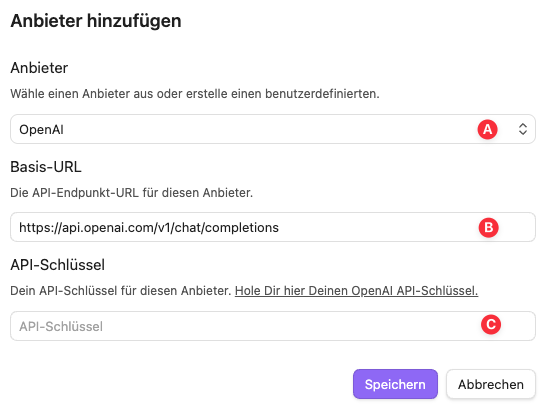
Modelle (5): Hier trägst du das Modell ein, das du vom jeweiligen Anbieter nutzen möchtest. Es lohnt sich, ein kostengünstiges Modell zu wählen. Was die einzelnen Modelle kosten, findest du auf der Webseite des Anbieters.
- Anbieter (A): Hier wählst du einen der Anbieter, die du oben eingestellt hast.
- Beliebte Modelle (B): Diese Modelle werden dir vorgeschlagen. Du kannst eines der voreingestellten Modelle auswählen oder ein anderes aus dem Angebot des Anbieters selbst konfigurieren. Falls du zum Beispiel mit Ollama lokale Modelle nutzen möchtest, muss das Modell auch installiert sein. Es wird dann aber nicht unbedingt an dieser Stelle angezeigt.
- Modellname (C): Hier kannst du den Namen wählen, der im Web Clipper angezeigt wird. Falls du eines der Modelle unter (B) ausgewählt hast, wird hier automatisch ein Name eingetragen, den du überschreiben kannst.
- Modell-ID (D): Das ist der technische Name des Modells, den du nicht ändern solltest. Wenn du ein anderes Modell als eines der vorgegebenen verwenden möchtest, musst du dich auf der Anbieter-Webseite informieren, wie die ID für das Modell lautet.
Ein Eintrag fehlt noch und das ist der Standard-Interpreter-Kontext:
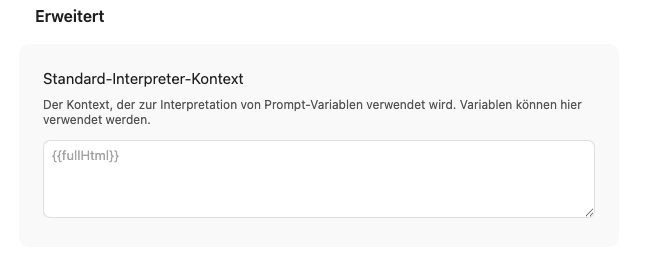
Hier kannst du einen allgemeinen Kontext eingeben, also definieren was vom Sprachmodell für die Auswertung verwendet werden soll. Vorgegeben ist das gesamte HTML. Da dies für alle Aufrufe der KI gilt, würde ich empfehlen das Feld leer zu lassen und den Kontext stattdessen direkt in der jeweiligen Vorlage zu definieren, wo er dann gezielt eingesetzt werden kann.
Zusammenfassung vor dem eigentlichen Inhalt
Sprachmodelle lassen sich im Kontext des Web Clippers gut einsetzen. Grundsätzlich lehne ich die Erstellung von Notizen mit künstlicher Intelligenz ab, aber als Hilfsmittel, zum Beispiel um Texte zusammenzufassen oder Kernpunkte herauszuarbeiten, ist die KI dann doch sehr hilfreich.
Beim Clippen von Webseiten und der späteren Auseinandersetzung mit dem Inhalt kann es hilfreich sein, wenn nicht nur der eigentliche Inhalt in der Notiz steht, sondern auch eine Zusammenfassung oder eine kurze Aufzählung. Das hilft besonders bei der Triage, also der Auswahl der Artikel die es wert sind weiter bearbeitet zu werden.
Dazu erstellst du, nachdem du in den Einstellungen einen Anbieter und ein Sprachmodell konfiguriert hast, eine neue Vorlage. Am besten kopierst du deine Standardvorlage, damit die Eigenschaften die du in deinem Vault verwendest bereits definiert sind.
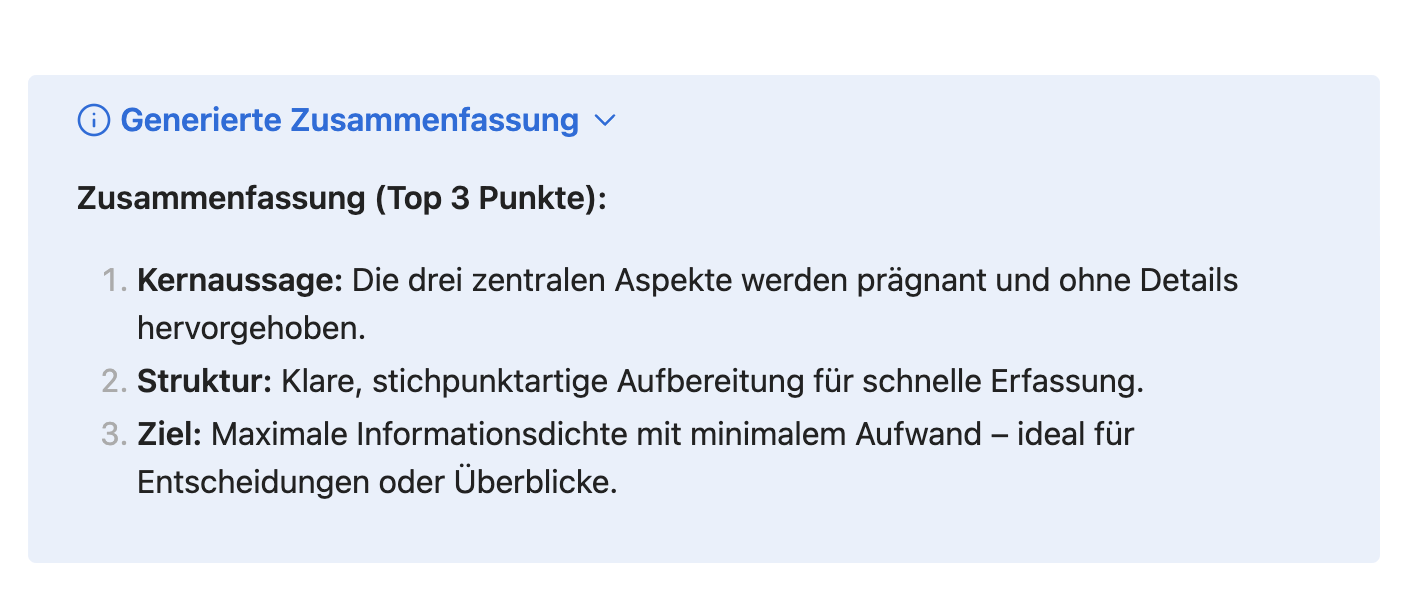
Die Auswertung über ein Sprachmodell wird durch einen Prompt ausgelöst, also die Beschreibung der Aufgabe für die KI. Das geschieht dadurch, dass du in der Box für den Notizinhalt einen Ausdruck wie {{"Erstelle eine kurze Zusammenfassung mit den 3 wichtigsten Punkten"}} einträgst. Das Ergebnis für die Personal Knowledge Management Seite sah zum Beispiel so aus, die ersten drei Aufzählungspunkte wurden von dem Sprachmodell (hier mit dem externen Modell „ggpt-5-mini”) erstellt:

Wenn du diesen generierten Bereich etwas mehr absetzen möchtest, kannst du den |callout-Filter nutzen. Der Notizinhalt lässt sich dann zum Beispiel so definieren:
{{"Erstelle eine kurze Zusammenfassung mit den 3 wichtigsten Punkten"|callout:("info","Generierte Zusammenfassung","true"}}
{{content}}
Der |callout-Filter nimmt drei Parameter. Der erste ist der Callout-Typ, hier info, der zweite ist die Überschrift, also "Generierte Zusammenfassung", und der dritte steuert ob der Callout eingeklappt dargestellt wird. true bedeutet eingeklappt, false bedeutet ausgeklappt, und ohne diesen Parameter wird ein normaler Callout ohne Klappmechanismus erstellt.
Das Ergebnis sieht dann so aus:

Oder aufgeklappt:
Englische Artikel auf Deutsch zusammenfassen
Ein praktischer Anwendungsfall ist das Zusammenfassen englischsprachiger Artikel direkt auf Deutsch. Der Prompt übernimmt dabei die Übersetzung automatisch mit:
{{"Fasse den Inhalt in 3 Punkten auf Deutsch zusammen, auch wenn der Originaltext auf Englisch ist"}}
Das spart den Umweg über ein separates Übersetzungswerkzeug und ist gerade beim Durcharbeiten einer größeren Sammlung geclippter englischer Artikel sehr nützlich.
Relevanz einschätzen statt zusammenfassen
Ein Sprachmodell kann nicht nur zusammenfassen, sondern auch einschätzen ob ein Artikel es überhaupt wert ist weiter gelesen zu werden. Das passt gut zur Triage und lässt sich mit einem einfachen Prompt umsetzen:
{{"Bewerte in einem Satz ob dieser Artikel für jemanden relevant ist der sich für PKM und Wissensmanagement interessiert. Antworte mit: Relevant, Bedingt relevant oder Nicht relevant, gefolgt von einer kurzen Begründung"}}
Das Ergebnis ist keine Zusammenfassung, sondern eine Einschätzung die dir hilft schnell zu entscheiden ob du den Artikel vertiefen möchtest oder nicht. Den Suchbegriff im Prompt kannst du natürlich an dein eigenes Themengebiet anpassen.
Tags generieren
Achte auch auf die Tag-Zeile in den Eigenschaften. Die Tags lassen sich ebenfalls mit dem Sprachmodell erstellen. Dazu trägst du die Abfrage direkt in das Eigenschaften-Feld für tags ein:
{{"Generiere 3 bis 5 passende Tags für diesen Inhalt als kommagetrennte Liste, nur Tags die aus einem Wort bestehen, keine Erklärung, ohne #-Zeichen"}}
Modellqualität
Die Qualität der Ergebnisse hängt stark vom gewählten Modell ab. Bei meinen Tests haben lokale Modelle meistens deutlich schlechter abgeschlossen als die OpenAI-Modelle. Da mein Mac nur 16 GB Hauptspeicher hat, konnte ich keine größeren lokalen Modelle fahren, die vielleicht bessere Ergebnisse geliefert hätten. Wer lokale Modelle einsetzt sollte die Ergebnisse daher kritisch prüfen, besonders bei der Tag-Generierung und der Relevanzeinschätzung.
Die Schnittstelle zu den Sprachmodellen im Obsidian Web Clipper bietet mit der Verwendung von Variablen und Filtern einige Möglichkeiten, die über eine einfache Zusammenfassung weit hinausgehen.
Fazit
Der Obsidian Web Clipper ist mehr als ein Werkzeug zum Speichern von Webseiten. Er ist ein flexibles System, das sich an den eigenen Workflow anpassen lässt, vom schnellen Bookmark bis zur strukturierten Notiz mit automatisch befüllten Eigenschaften, KI-Zusammenfassung und direkten Links zurück zur Originalquelle.
Die Vorlagen sind dabei das zentrale Konzept. Mit Variablen, Filtern und den drei zusätzlichen Variablentypen Schema, Meta und Selektor lässt sich fast jede Webseite so clippen, dass das Ergebnis direkt in den eigenen Wissenskontext passt. An zwei Stellen in diesem Artikel habe ich auch die Logik-Funktionen des Web Clippers eingesetzt, den ??-Operator als Fallback und die {% for %}-Schleife für die Besetzungsliste. Das sind nur zwei Beispiele aus einer vollständigen Template-Sprache, die Bedingungen, Schleifen und Variablenzuweisungen ermöglicht und die Vorlagen nochmals deutlich mächtiger macht. Die vollständige Dokumentation dazu findet sich unter obsidian.md/help/web-clipper/logic.
Was der Web Clipper aber nicht leisten kann, ist die „Triage“ und das „Treatment“, also die eigentliche Auseinandersetzung mit dem Inhalt. Er kann den „Intake“ erleichtern und mit der richtigen Vorlage sogar einen ersten Anreiz zur Reflexion setzen, wie etwa mit dem Bereich „Meine Gedanken dazu” in der Auswahl-Vorlage. Die Wissensarbeit selbst bleibt aber deine Aufgabe.
Im nächsten Kapitel gebe ich auch noch einen Überblick über die Einstellungen des Obsidian Web Clipper.